pandasのplotメソッドでグラフを作成しデータを可視化
pandas.Series, pandas.DataFrameのメソッドとしてplot()がある。Pythonのグラフ描画ライブラリMatplotlibのラッパーで、簡単にグラフを作成できる。
Irisデータセットを例として、様々な種類のグラフ作成および引数の設定などをサンプルコード・結果とともに説明する。
- Irisデータセット
plot()メソッドの基本的な使い方- 表示
- 画像ファイルとして保存
- オブジェクトとして操作
- 共通の設定
- サイズを変更
- 別々のサブプロットに描画
- サブプロットのレイアウト
- サブプロットのx軸, y軸の共通化
- プロットする列の指定
- グラフの種類
- 折れ線グラフ(line plot)
- 棒グラフ(bar plot)
- 箱ひげ図(box plot)
- ヒストグラム(histogram)
- カーネル密度推定(Kernel Density Estimation plot)
- 面グラフ(area plot)
- 散布図(scatter plot)
- 六角形ビニング図(hexbin plot)
- ビジュアライゼーションライブラリseabornを使ったグラフ作成
- ヒートマップ
- ペアプロット図(散布図行列)
各種ライブラリを以下のようにインポートする。
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
Irisデータセット
irisデータセットは機械学習でよく使われるアヤメの品種データ。
150件のデータがSetosa, Versicolor, Virginicaの3品種に分類されており、それぞれ、Sepal Length(がく片の長さ), Sepal Width(がく片の幅), Petal Length(花びらの長さ), Petal Width(花びらの幅)の4つの特徴量を持っている。
様々なライブラリにテストデータとして入っている。
- The Iris Dataset — scikit-learn 0.19.0 documentation
- [https://github.com/pandas-dev/pandas/blob/master/pandas/tests/io/data/csv/iris.csv](https://github.com/pandas-dev/pandas/blob/master/pandas/tests/io/data/csv/iris.csv
- https://github.com/mwaskom/seaborn-data/blob/master/iris.csv
pandas.DataFrameとして読み込む。
df = pd.read_csv('data/src/iris.csv', index_col=0)
print(df.head())
# sepal_length sepal_width petal_length petal_width species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosa
species列には3種類の品種が文字列で格納され、残り4つの列はそれぞれの特徴量が数値で格納される。
plot()メソッドの基本的な使い方
表示
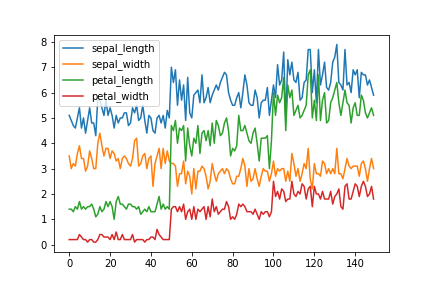
pandas.Seriesまたはpandas.DataFrameからplot()メソッドを呼ぶとデフォルトでは折れ線グラフが描画される。
グラフ化されるのは数値の列のみで文字列の列は除外される。indexがx軸として使われる。
Jupyter Notebookの場合、先に%matplotlib inlineを実行しておくとグラフがインラインで表示される。
df.plot()
画像ファイルとして保存
画像ファイルとして保存する場合はplt.savefig()、ファイル保存ではなくOSの画像表示プログラムで表示する場合はplt.show()を使う。
繰り返しグラフを作成する場合はplt.figure()で初期化しないと、前の結果が残ることがあるので注意。Jupyter Notebookでインライン表示する場合は特に初期化の必要はない。
また、繰り返しplt.figure()を実行すると以下のような警告が出る場合がある。
RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface
(`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory.
(To control this warning, see the rcParam `figure.max_open_warning`). max_open_warning, RuntimeWarning)
plt.savefig()のあとでplt.close('all')を実行すればOK。
plt.figure()
df.plot()
plt.savefig('data/dst/pandas_iris_line.png')
plt.close('all')
オブジェクトとして操作
plot()メソッドが返すのはMatplotlibのAxesSubplotオブジェクト。
print(type(df.plot()))
# <class 'matplotlib.axes._subplots.AxesSubplot'>
デフォルトではアクティブなサブプロットに描画されるが、plot()の引数axで任意のサブプロットを指定して描画できる。
上のpyplotインターフェイスと同様のグラフを生成する例。
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
df.plot(ax=ax)
fig.savefig('data/dst/pandas_iris_line.png')
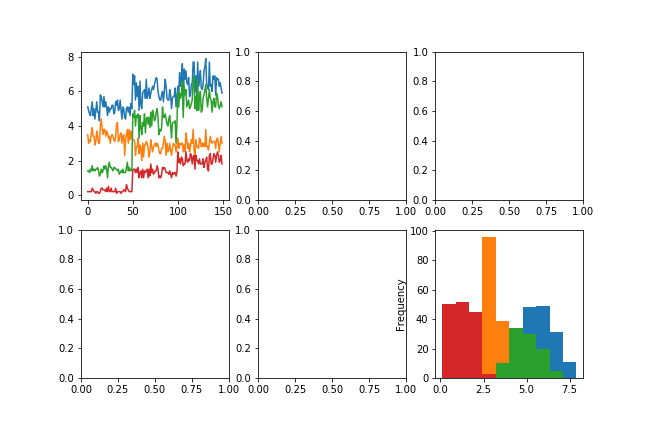
plt.subplots()を使って複数のサブプロットを並べる例。
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(9, 6))
df.plot(ax=axes[0, 0], legend=False)
df.plot(ax=axes[1, 2], legend=False, kind='hist')
fig.savefig('data/dst/pandas_iris_line_axes.png')
軸axisの細かい設定を調整したい場合などはこちらのオブジェクト指向インターフェイスを使う。
なお、引数の設定、グラフの種類によってはplot()はMatplotlibのAxesSubplotオブジェクトを要素とするNumPy配列numpy.ndarrayを返すこともあるので注意。
共通の設定
plot()では様々な種類のグラフをプロットできる。まず共通の設定を説明する。
サイズを変更
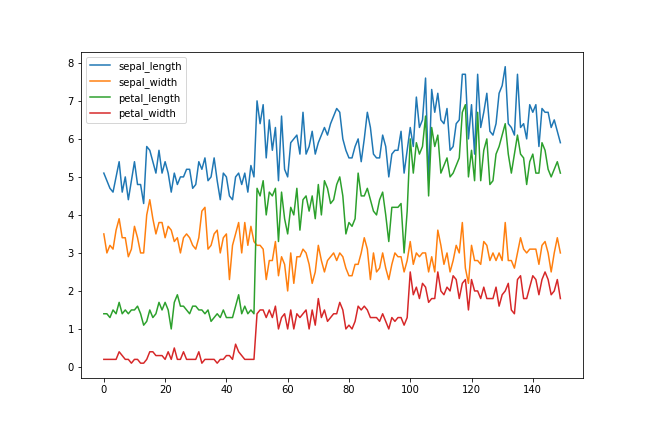
生成される画像のサイズはfigsize(単位: インチ)とdpi(インチ当たりのドット数)で決定される。
それぞれ以下のように確認および変更ができる。
figsizeはpandasのplot()メソッド、または、plt.figure(), plt.subplots()の引数として指定する。
current_figsize = mpl.rcParams['figure.figsize']
print(current_figsize)
# [6.0, 4.0]
plt.figure()
df.plot(figsize=(9, 6))
plt.savefig('data/dst/pandas_iris_line_figsize.png')
plt.close('all')
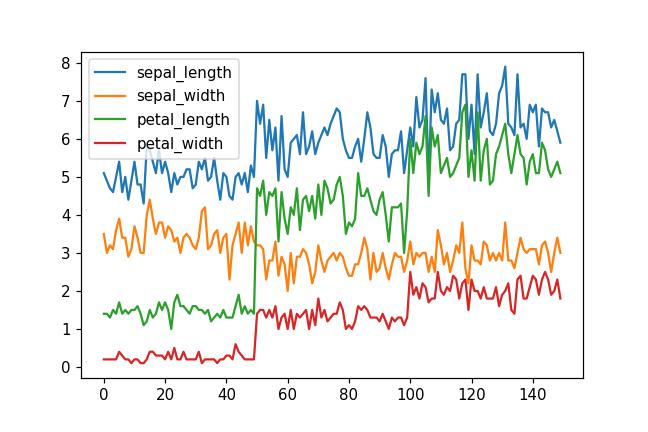
dpiはsavefig()の引数として指定する。
current_dpi = mpl.rcParams['figure.dpi']
print(current_dpi)
# 72.0
plt.figure()
df.plot()
plt.savefig('data/dst/pandas_iris_line_dpi.png', dpi=current_dpi * 1.5)
plt.close('all')
各列を別々のサブプロットにプロット: 引数subplots
引数subplots=Trueとすると各列が別々のサブプロットにプロットされる。
以降のサンプルコードではplt.figure(), plt.savefig(), plt.closeを省略する。
df.plot(subplots=True)

この場合、AxesSubplotオブジェクトを要素とするNumPy配列numpy.ndarrayが返される。
print(type(df.plot(subplots=True)))
print(type(df.plot(subplots=True)[0]))
# <class 'numpy.ndarray'>
# <class 'matplotlib.axes._subplots.AxesSubplot'>
サブプロットのレイアウト: 引数layout
引数layoutにサブプロットの行数、列数をタプルで指定できる。
df.plot(subplots=True, layout=(2, 2))
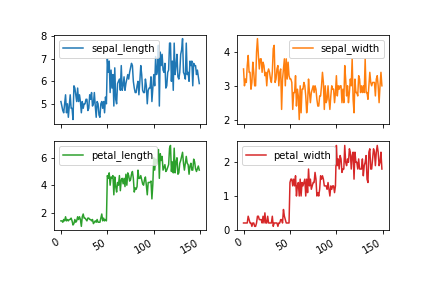
サブプロットのx軸, y軸の範囲の共通化: 引数sharex, sharey
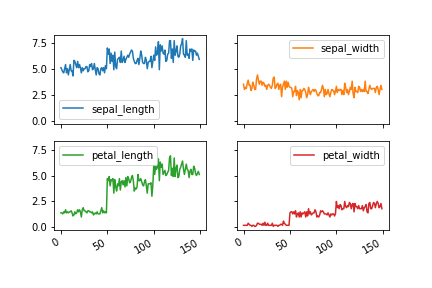
引数sharex, shareyをTrueとすると、それぞれx軸、y軸の範囲が共通化される。
df.plot(subplots=True, layout=(2, 2),
sharex=True, sharey=True)
プロットする列の指定: 引数x, y
これまでの例のように、デフォルトではpandas.DataFrameからplot()メソッドを呼ぶと、数値の列すべてがプロットされ、indexがx軸として使われる。
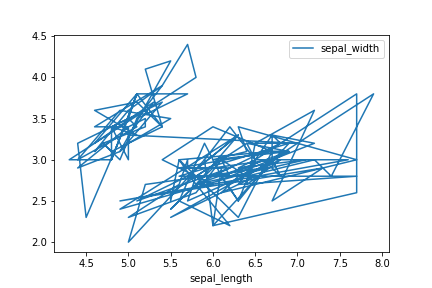
引数x, yに列名を指定することでx軸, y軸としてプロットする列を選択できる。例は折れ線グラフなのでよく分からない結果となるが、散布図などの場合には重要な設定。散布図については後述。
df.plot(x='sepal_length', y='sepal_width')
xのみ指定した場合は、残りの列がy軸としてプロットされる。
df.plot(x='sepal_length')

yのみ指定した場合は、x軸がindex、指定した列がy軸としてプロットされる。
df.plot(y='sepal_length')

引数x, yにリストで複数の列名を指定すると警告UserWarningが出る。
# df.plot(y=['sepal_length', 'sepal_width'])
# UserWarning: Pandas doesn't allow columns to be created via a new attribute name
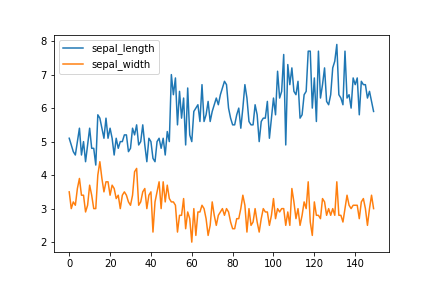
複数の列を重ねてプロットしたい場合は、1つ目のplot()で取得できるAxesSubplotを2つ目以降のplot()の引数axに指定する。
ax = df.plot(y='sepal_length')
df.plot(y='sepal_width', ax=ax)
プロットに使う列のみを選択したpandas.DataFrameでplot()メソッドを呼んでも同じ結果が得られる。こっちのほうが楽かもしれない。
df[['sepal_length', 'sepal_width']].plot()
そのほか見た目の設定
そのほか、
- 引数
title: グラフタイトル - 引数
grid: グリッドの有無 - 引数
colormap: 色 - 引数
legend: 凡例の有無 - 引数
alpha: 透過率(0〜1)
などが設定できる。
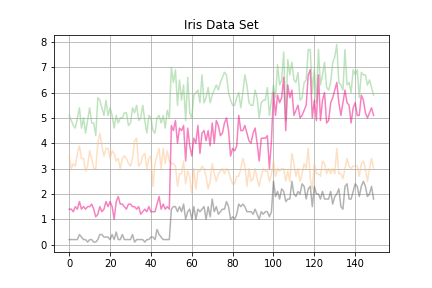
df.plot(title='Iris Data Set',
grid=True,
colormap='Accent',
legend=False,
alpha=0.5)
colormapで指定できる色(カラーマップ)の種類は以下のMatplotlibの公式サイトを参照。
グラフの種類: 引数kind
引数kindでグラフの種類を指定できる。
'line': 折れ線グラフ(line plot)'bar': 垂直棒グラフ(vertical bar plot)'barh': 水平棒グラフ(horizontal bar plot)'box': 箱ひげ図(boxplot)'hist': ヒストグラム(histogram)'kde','density': カーネル密度推定(Kernel Density Estimation plot)'area': 面グラフ(area plot)'scatter': 散布図(scatter plot)'hexbin': hexbin plot'pie': 円グラフ(pie plot)
バージョン0.17.0から、上記のグラフの種類をplot()メソッドのアクセサとして記述できるようになった。
例えばdf.plot(kind='line')とdf.plot.line()は同じ。
df.plot(kind='line')
df.plot.line()
plot.line()でもここまで説明してきたplot()の引数がそのまま使える。
df.plot.line(subplots=True, layout=(2, 2))
それぞれのグラフの種類に対応するMatplotlibのメソッドの引数もキーワード引数として設定できる。
折れ線グラフ(line plot)
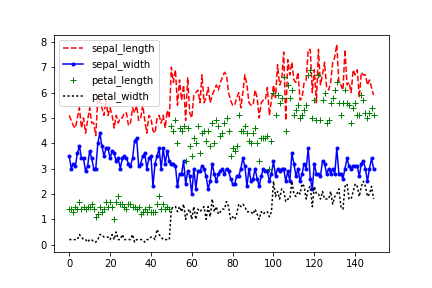
折れ線グラフはplot.line()。
線種や色、マーカーは引数styleに文字列'[color][marker][line]'で指定する。
color:r(赤),g(緑),b(青),k(黒)などmarker:o(丸),.(点),s(四角),+(プラス)などline:-(破線),--(破線),:(点線)など
例えば赤い破線に四角のマーカーは'rs--'。color, marker, lineをすべて含む必要はなく、省略も可能。
それぞれの種類一覧は以下のMatplotlib公式サイト参照。中段のNoteに書いてある。
各プロットに対して個別に指定したい場合は引数styleに文字列のリストを指定する。
df.plot.line(style=['r--', 'b.-', 'g+', 'k:'])
棒グラフ(bar plot)
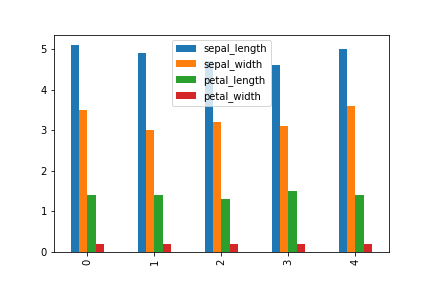
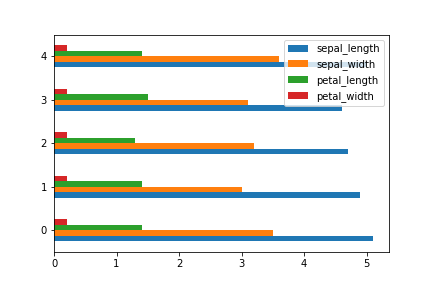
垂直棒グラフはplot.bar(), 水平棒グラフはplot.barh()。
行数が多いと見にくいので最初の5行分のデータのみ使用している。
df[:5].plot.bar()
df[:5].plot.barh()
引数stacked=Trueとすると積み上げ棒グラフになる。
df[:5].plot.bar(stacked=True)
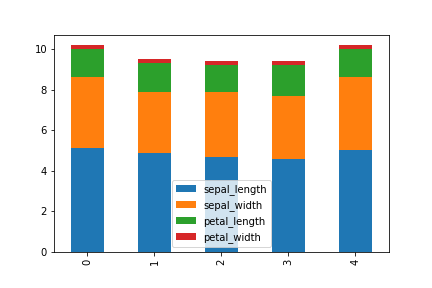
棒グラフ独自の引数はMatplotlibの公式サイト参照。
- matplotlib.pyplot.bar — Matplotlib 2.2.2 documentation
- matplotlib.pyplot.barh — Matplotlib 2.2.2 documentation
箱ひげ図(box plot)
箱ひげ図はplot.box()。
最小値、第1四分位点、中央値、第3四分位点、最大値が表される。丸は外れ値。
df.plot.box()
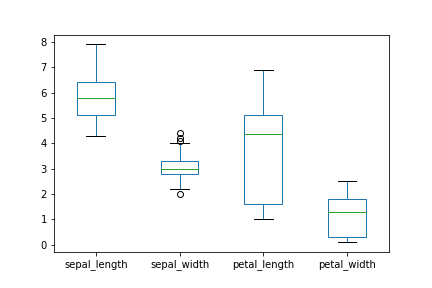
箱ひげ図独自の引数はMatplotlibの公式サイト参照。
ヒストグラム(histogram)
ヒストグラムはplot.hist()。
plt.savefig('data/dst/pandas_iris_hist.png')
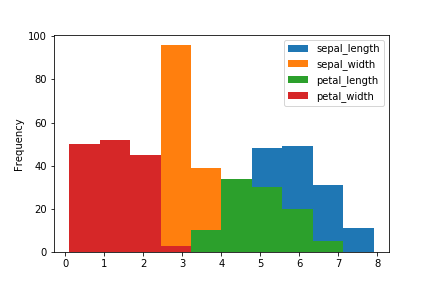
透過率は引数alpha。
df.plot.hist(alpha=0.5)
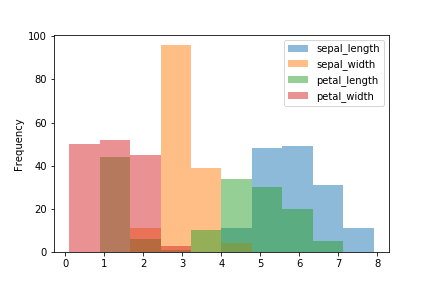
引数stacked=Trueで積み上げヒストグラム。
df.plot.hist(stacked=True)
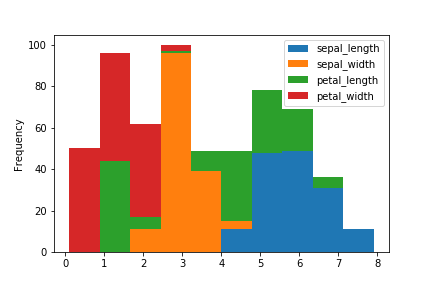
ヒストグラム独自の引数はMatplotlibの公式サイト参照。
引数binsで分割数を指定したり、histtypeでタイプを指定したり、orientationで横向きにしたりできる。
df.plot.hist(bins=20, histtype='step', orientation='horizontal')

カーネル密度推定(Kernel Density Estimation plot)
カーネル密度推定の分布図はplot.kde()。
線の種類、色は折れ線グラフと同様、引数styleで指定できる。上の折れ線グラフの項を参照。
df.plot.kde(style=['r-', 'g--', 'b-.', 'c:'])
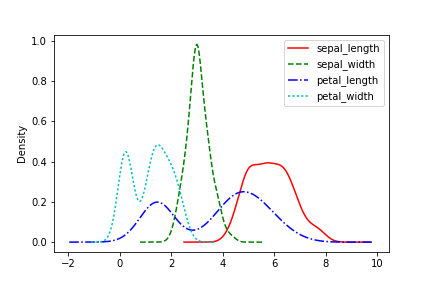
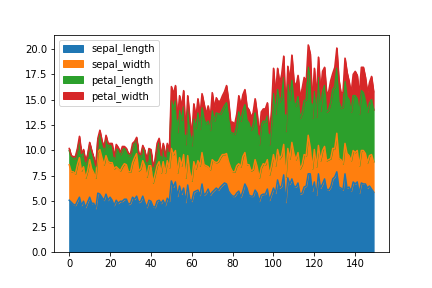
面グラフ(area plot)
面グラフはplot.area()。
デフォルトで積み上げ面グラフとなる。積み上げを無効にしたい場合は引数stacked=False。
df.plot.area()
散布図(scatter plot)
散布図はplot.scatter()。
x軸、y軸としてプロットする列の列名をそれぞれ引数x, yに指定する。
df.plot.scatter(x='sepal_length', y='petal_length', alpha=0.5)
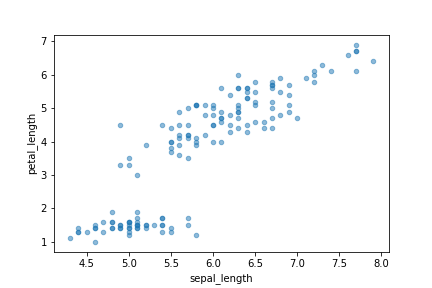
上の共通の設定の項で説明したように、複数のプロットを重ねる場合は1つ目のplot()で取得できるAxesSubplotを2つ目以降のplot()の引数axに指定する。
マーカーの種類は引数marker、色は引数c、サイズは引数sで指定する。cとsはリストで指定することも可能。
そのほか散布図独自の引数はMatplotlibの公式サイト参照。
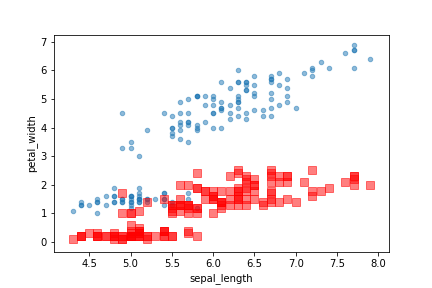
ax = df.plot.scatter(x='sepal_length', y='petal_length', alpha=0.5)
df.plot.scatter(x='sepal_length', y='petal_width',
marker='s', c='r', s=50, alpha=0.5, ax=ax)
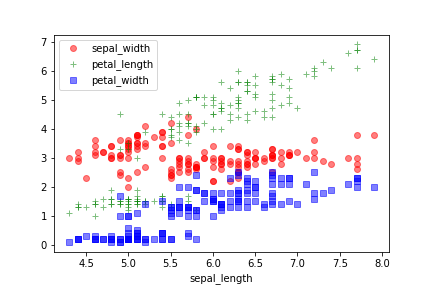
なお、折れ線グラフの引数styleでマーカーを指定して線種を省略すると散布図と同様のグラフが描画できる。こっちのほうが楽かもしれない。お好みで。
df.plot.line(x='sepal_length',
style=['ro', 'g+', 'bs'], alpha=0.5)
六角形ビニング図(hexbin plot)
日本語の正しい名称を知らないが、散布図での六角形のエリアに入る点の数を色の濃さで表したグラフ。同じ位置に多数の点が重なってプロットされるようなデータの分布が見やすい。
散布図と同様にx軸、y軸としてプロットする列の列名をそれぞれ引数x, yに指定する。
hexbin独自の引数はMatplotlibの公式サイト参照。
引数gridsizeはx軸方向の六角形の数。小さくなると六角形が大きく、粗いグラフになる。
df.plot.hexbin(x='sepal_length', y='petal_length',
gridsize=15, sharex=False)
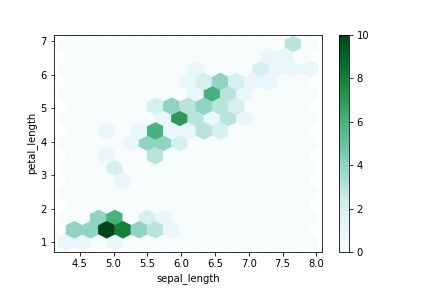
デフォルトだとx軸のラベルが表示されないpandasのバグがある。バージョン0.22.0時点でまだFixされていないが、sharex=Falseとすればとりあえず表示されるようになる。
円グラフ(pie plot)
円グラフはplot.pie()。
Irisのデータだとよく分からないので別のデータを例とする。
df_pie = pd.DataFrame([[1, 50], [2, 20], [3, 30]],
index=['a', 'b', 'c'], columns=['ONE', 'TWO'])
print(df_pie)
# ONE TWO
# a 1 50
# b 2 20
# c 3 30
pandas.DataFrameに対しては引数subplots=Trueとして列毎に個別にプロットしないとエラーになる。
df_pie.plot.pie(subplots=True)
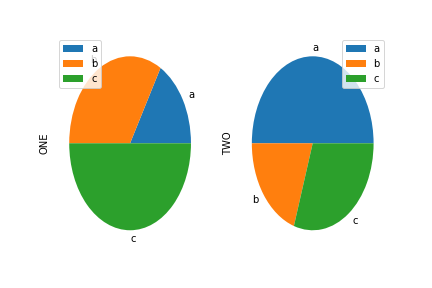
AxesSubplotオブジェクトを要素とするNumPy配列numpy.ndarrayが返される。
print(type(df_pie.plot.pie(subplots=True)))
print(type(df_pie.plot.pie(subplots=True)[0]))
# <class 'numpy.ndarray'>
# <class 'matplotlib.axes._subplots.AxesSubplot'>
特定の列の円グラフを生成したい場合は、列を指定してplot.pie()を呼ぶ。
df_pie['ONE'].plot.pie()

ビジュアライゼーションライブラリseabornを使ったグラフ作成
ビジュアライゼーションライブラリseabornを使うとそのほかの種類のグラフを作成できる。
ヒートマップ
二次元データからヒートマップを作成できる。
pandas.DataFrameを使うと列名・行名がそのままx軸・y軸のラベルになる。
下の例はIrisではなく別のデータの各列間の相関係数を可視化したもの。
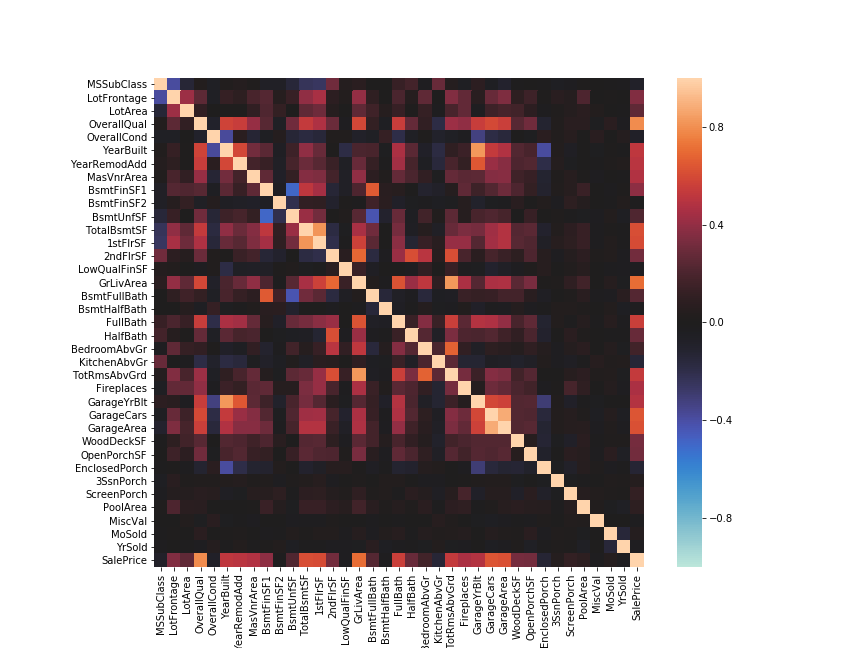
詳細は以下の記事を参照。
ペアプロット図(散布図行列)
ペアプロット図(散布図行列)も作成できる。
列同士の関係をざっくり確認するのに便利。
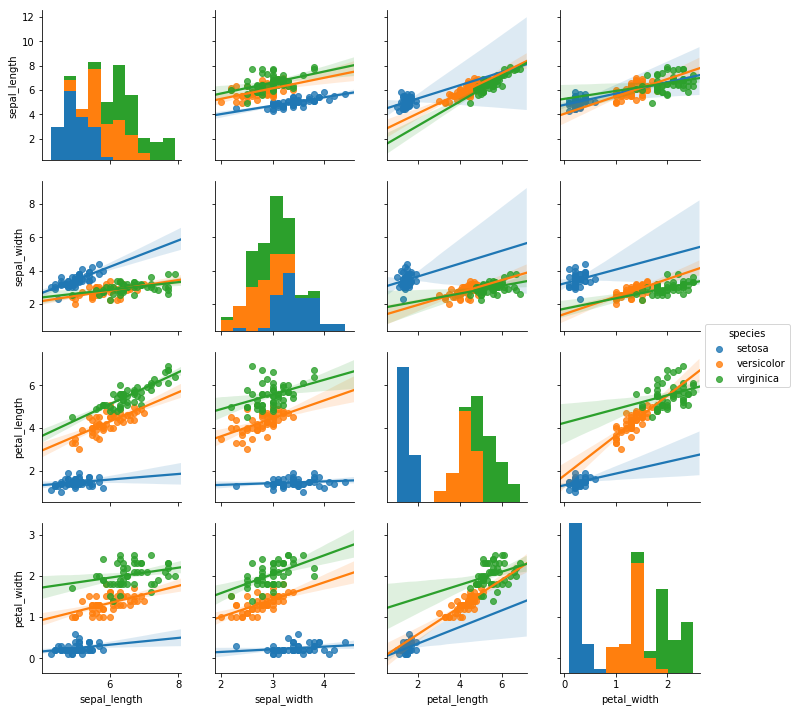
詳細は以下の記事を参照。