scikit-learnのSVMでirisデータセットを分類
irisデータセット
irisデータセットは機械学習でよく使われるアヤメの品種データ。
150件のデータがSetosa, Versicolor, Virginicaの3品種に分類されており、それぞれ、Sepal Length(がく片の長さ), Sepal Width(がく片の幅), Petal Length(花びらの長さ), Petal Width(花びらの幅)の4つの特徴量を持っている。
様々なライブラリにテストデータとして入っている。
- The Iris Dataset — scikit-learn 0.19.0 documentation
- https://github.com/pandas-dev/pandas/blob/master/pandas/tests/io/data/csv/iris.csv
- https://github.com/mwaskom/seaborn-data/blob/master/iris.csv
seabornで可視化
まず雰囲気をつかむためにseabornで可視化してみる。
公式ドキュメントでもpairplotの例としてirisデータセットが使われている。
コードはこんな感じ。load_dataset("iris")でirisデータセットをpandasのDataFrameとして読んで、pairplot()でグラフ化。
import seaborn as sns
sns.set(style="ticks")
df = sns.load_dataset("iris")
# http://seaborn.pydata.org/generated/seaborn.pairplot.html
sns.pairplot(df, hue='species', markers=["o", "s", "+"]).savefig('data/dst/seaborn_iris.png')
それぞれの特徴量の相関を示している。
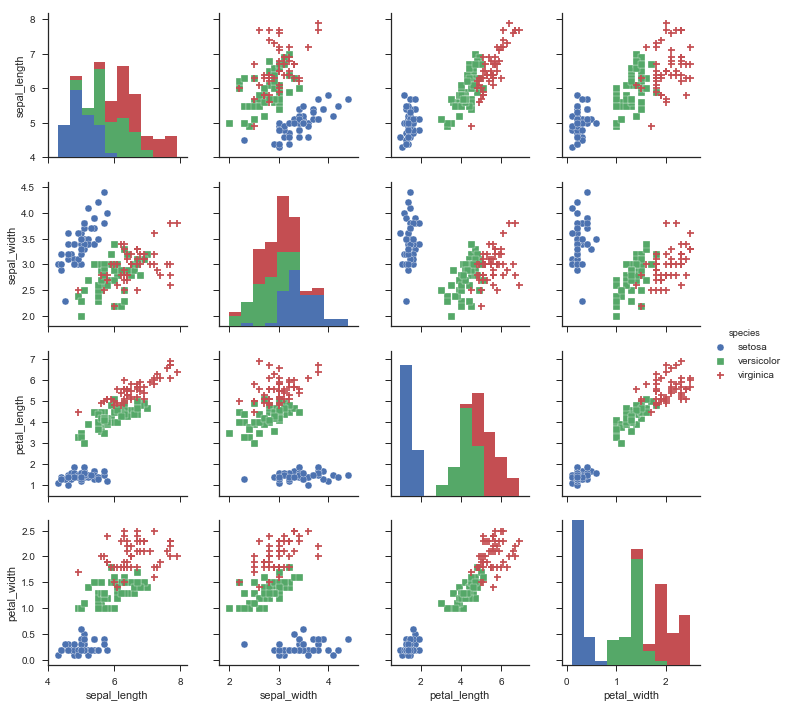
VersicolorとVirginicaは比較的似ていることが分かる。
scikit-learnのSVMで分類
scikit-learnのSVM(サポートベクターマシン)で分類してみる。
データ読み込み
まずはirisデータセットの読み込み。上のseabornのデータを使ってもいいが、ここではscikit-learnに含まれているデータを使う。
import pandas as pd
from sklearn import datasets, model_selection, svm, metrics
# http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html
# http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
iris = datasets.load_iris()
print(type(iris))
print(iris.keys())
# <class 'sklearn.datasets.base.Bunch'>
# dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
datasets.load_iris()で読むと、seabornとは違い、辞書ライクなデータとして受け取れる。
4つの特徴量と分類ラベルをそれぞれpandasのDataFrameとSeriesとして格納する。データ数は150件。head()で最初の5件だけ出力している。
iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
print(iris_data.head())
# sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
# 0 5.1 3.5 1.4 0.2
# 1 4.9 3.0 1.4 0.2
# 2 4.7 3.2 1.3 0.2
# 3 4.6 3.1 1.5 0.2
# 4 5.0 3.6 1.4 0.2
iris_label = pd.Series(data=iris.target)
print(iris_label.head())
# 0 0
# 1 0
# 2 0
# 3 0
# 4 0
# dtype: int64
print(len(iris_data))
# 150
学習用とテスト用に分割
データを学習用とテスト用に分割する。model_selection.train_test_split()を使うと簡単。シャッフルしていい感じに分割してくれる。デフォルトではtest_size=0.25になっており、今回の場合は、学習用が112件、テスト用が38件に分割される。
# http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
data_train, data_test, label_train, label_test = model_selection.train_test_split(iris_data, iris_label)
print(data_train.head())
# sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
# 55 5.7 2.8 4.5 1.3
# 128 6.4 2.8 5.6 2.1
# 142 5.8 2.7 5.1 1.9
# 97 6.2 2.9 4.3 1.3
# 130 7.4 2.8 6.1 1.9
print(label_train.head())
# 55 1
# 128 2
# 142 2
# 97 1
# 130 2
# dtype: int64
# default value of test_size = 0.25
print(len(data_train), len(data_test))
# 112 38
SVMで学習
データが準備できたので、学習用データをSVMで学習させ、テスト用データの分類予測結果を得る。
clf = svm.SVC()
clf.fit(data_train, label_train)
pre = clf.predict(data_test)
print(type(pre))
print(pre)
# <class 'numpy.ndarray'>
# [0 0 1 1 0 0 0 0 0 2 1 0 0 0 2 1 1 2 2 2 2 1 0 1 1 1 2 0 2 2 0 2 0 2 0 1 0
# 0]
predict()の出力はndarray(NumPyの配列)。
結果確認
どれくらい正しく分類できたか確認する。metrics.accuracy_score()を使うと簡単に正解率を算出できる。
# http://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html
ac_score = metrics.accuracy_score(label_test, pre)
print(ac_score)
# 0.973684210526
学習用とテスト用に分割する時にデータをシャッフルするので実行するたびに結果は変わるが、100%に近い確率で分類できている。