Python, pandas, seabornでペアプロット図(散布図行列)を作成
Pythonのビジュアライゼーションライブラリseabornとpandasを使うと、ペアプロット図(散布図行列)を簡単に作成できる。
seaborn.pairplot()関数を使う。
第一引数にpandas.DataFrameを指定するだけで各列同士の散布図がマトリクス上に配置されたペアプロット図が作成できる。対角線にはヒストグラムが配置される。
Irisデータセットを例に、各種引数による設定などを説明する。
- Irisデータセット
seaborn.pairplot()関数の使い方とデフォルト設定- カテゴリデータに従って色分け: 引数
hue- カテゴリの順番を指定: 引数
hue_order - カテゴリの色を指定: 引数
palette
- カテゴリの順番を指定: 引数
- グラフ化する列を指定: 引数
vars,x_vars,y_vars - マーカーを指定: 引数
markers - 回帰直線を重ねてプロット: 引数
kind - 対角線のグラフの種類をカーネル密度分布に変更: 引数
diag_kind - サイズを指定: 引数
size - その他の引数: 引数
plot_kws,diag_kws
Jupyter Notebookでグラフをインラインで表示したい場合は%matplotlib inlineを実行しておく。
Irisデータセット
irisデータセットは機械学習でよく使われるアヤメの品種データ。
150件のデータがSetosa, Versicolor, Virginicaの3品種に分類されており、それぞれ、Sepal Length(がく片の長さ), Sepal Width(がく片の幅), Petal Length(花びらの長さ), Petal Width(花びらの幅)の4つの特徴量を持っている。
様々なライブラリにテストデータとして入っている。
- The Iris Dataset — scikit-learn 0.19.0 documentation
- [https://github.com/pandas-dev/pandas/blob/master/pandas/tests/io/data/csv/iris.csv](https://github.com/pandas-dev/pandas/blob/master/pandas/tests/io/data/csv/iris.csv
- https://github.com/mwaskom/seaborn-data/blob/master/iris.csv
pandas.DataFrameとして読み込む。seabornではsns.load_dataset("iris")で読み込むこともできる。
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/src/iris.csv', index_col=0)
# df = sns.load_dataset("iris")
species列には3種類の品種が文字列で格納され、残り4つの列はそれぞれの特徴量が数値で格納される。
print(df.head())
# sepal_length sepal_width petal_length petal_width species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosa
print(df.dtypes)
# sepal_length float64
# sepal_width float64
# petal_length float64
# petal_width float64
# species object
# dtype: object
print(df['species'].value_counts())
# versicolor 50
# setosa 50
# virginica 50
# Name: species, dtype: int64
seaborn.pairplot()関数の使い方とデフォルト設定
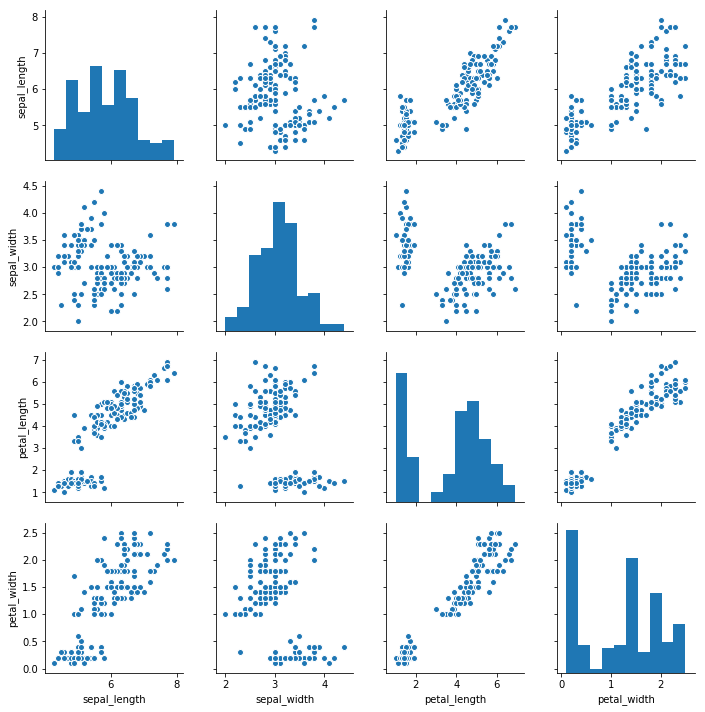
デフォルトのままグラフを作成するにはpairplot()関数の第一引数にpandas.DataFrameのオブジェクトをそのまま指定する。
seaborn.PairGridという型が返る。
pg = sns.pairplot(df)
print(type(pg))
# <class 'seaborn.axisgrid.PairGrid'>
savefig()メソッドで画像ファイルとして保存できる。
pg.savefig('data/dst/seaborn_pairplot_default.png')
続けて書いてもOK。
sns.pairplot(df).savefig('data/dst/seaborn_pairplot_default.png')
Jupyter Notebookの場合は先に%matplotlib inlineを実行しておいてからpairplot()を実行するとグラフがインラインで表示される。
結果を見ると分かるように、pairplot()関数では自動的に数値の列のみが選択されペアプロット図が作成される。Irisの例ではspecies列が無視される。
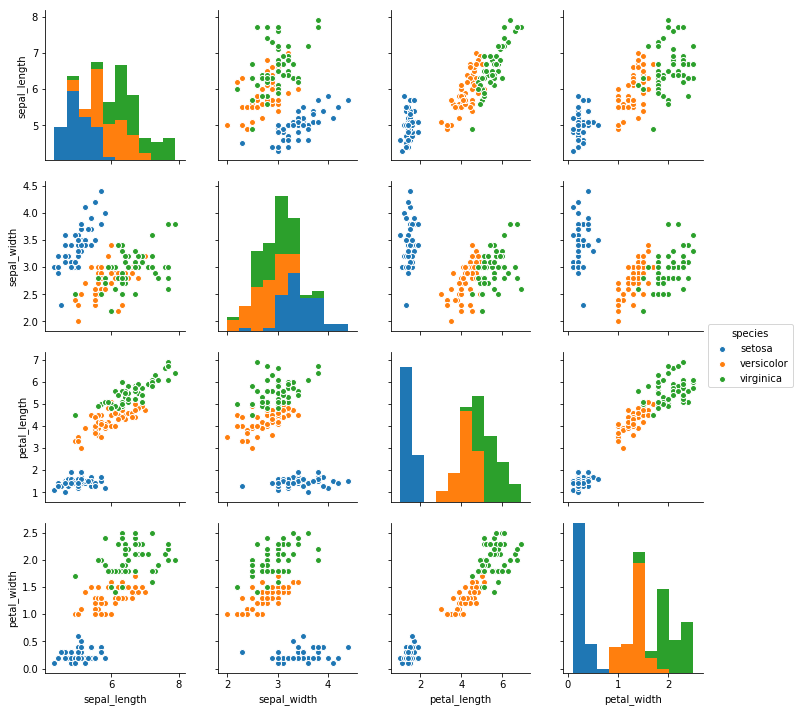
カテゴリデータに従って色分け: 引数hue
引数hueにカテゴリデータが格納された列の列名を指定すると、そのカテゴリごとに色分けしたグラフが生成される。
アイリスの場合は品種データが格納された列の列名speciesを指定する。
sns.pairplot(df, hue='species').savefig('data/dst/seaborn_pairplot_hue.png')
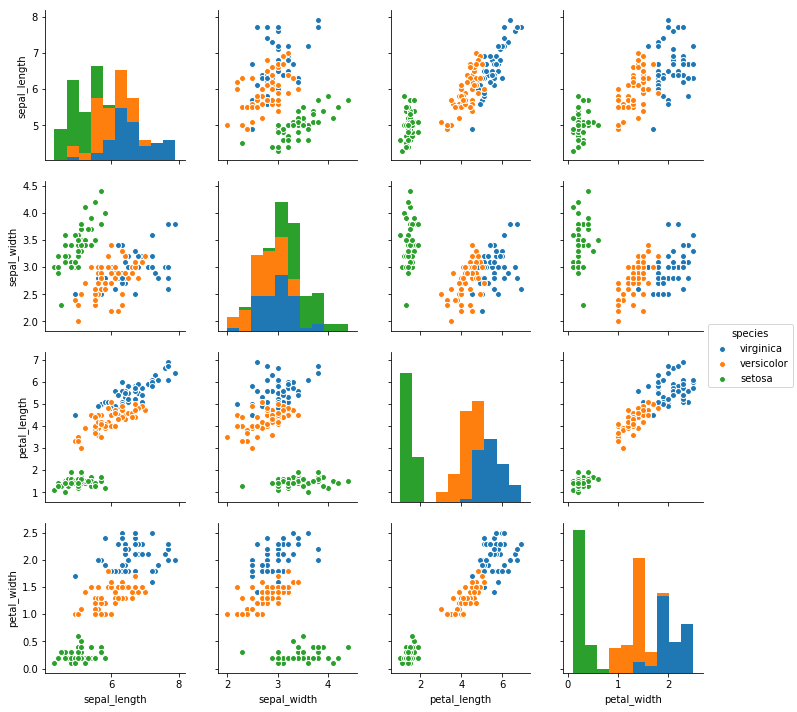
カテゴリの順番を指定: 引数hue_order
カテゴリの順番を指定したい場合は、引数hue_orderにリストで指定する。
sns.pairplot(df, hue='species',
hue_order=['virginica', 'versicolor', 'setosa']).savefig('data/dst/seaborn_pairplot_hue_order.png')
カテゴリの色を指定: 引数palette
カテゴリの色を指定したい場合は、引数paletteを指定する。
カラーマップ名を指定
Matplotlibで使えるカラーマップがそのまま使える。以下のMatplotlibの公式サイトにカラーマップが挙げられている。
sns.pairplot(df, hue='species', palette='Blues').savefig('data/dst/seaborn_pairplot_palette.png')

個別に色を指定
カラーマップではなく各カテゴリ名と色を辞書形式で個別に指定することもできる。
色は'red'や'blue'のような名前やRGBの16進数(HEX)表記'#xxxxxx'などで指定できる。以下のMatplotlibの公式サイトに色の名称の一覧が挙げられている。
sns.pairplot(df, hue='species',
palette={'setosa': 'red',
'versicolor': '#00ff00',
'virginica': 'blue'}).savefig('data/dst/seaborn_pairplot_palette_dict.png')
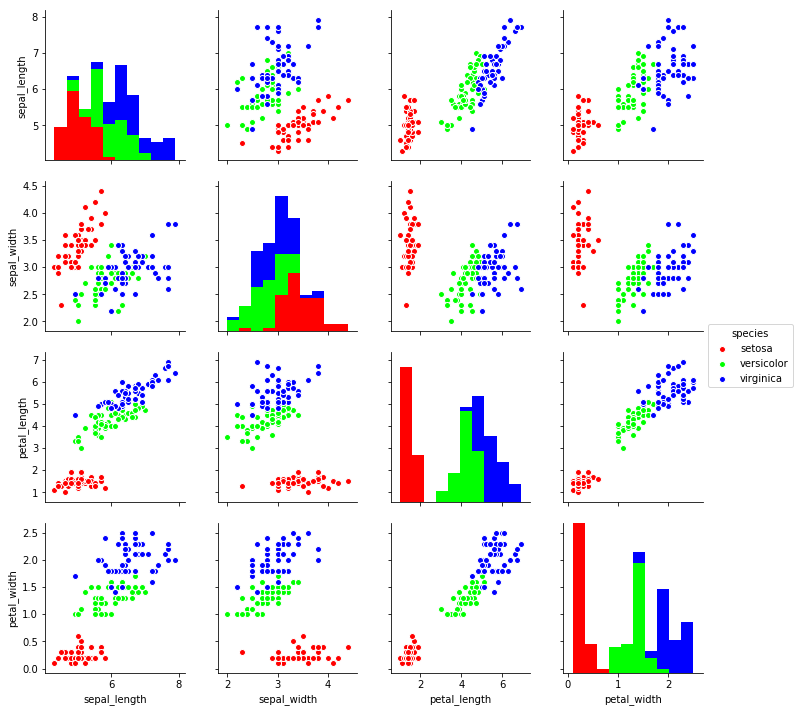
グラフ化する列を指定: 引数vars, x_vars, y_vars
上述のようにデフォルトでは数値の列がすべてグラフ化される。
グラフ化する列を選択するには、引数varsまたは引数x_varsと y_varsを指定する。グラフ化したい列名をリストで指定する。
sns.pairplot(df, hue='species',
vars=['sepal_length', 'sepal_width']).savefig('data/dst/seaborn_pairplot_vars.png')

sns.pairplot(df, hue='species',
x_vars=['sepal_length', 'sepal_width'],
y_vars=['petal_length', 'petal_width']).savefig('data/dst/seaborn_pairplot_xy_vars.png')

マーカーを指定: 引数markers
グラフのマーカーは引数markersで指定する。
マーカーの種類一覧は以下のMatplotlibの公式サイトを参照。
一つだけ指定するとすべてのマーカーが変更される。
sns.pairplot(df, hue='species', markers='+').savefig('data/dst/seaborn_pairplot_markers.png')

引数hueを設定した上で引数markersにリストで指定するとカテゴリごとに別々のマーカーを指定できる。
sns.pairplot(df, hue='species', markers=['+', 's', 'd']).savefig('data/dst/seaborn_pairplot_markers_multi.png')

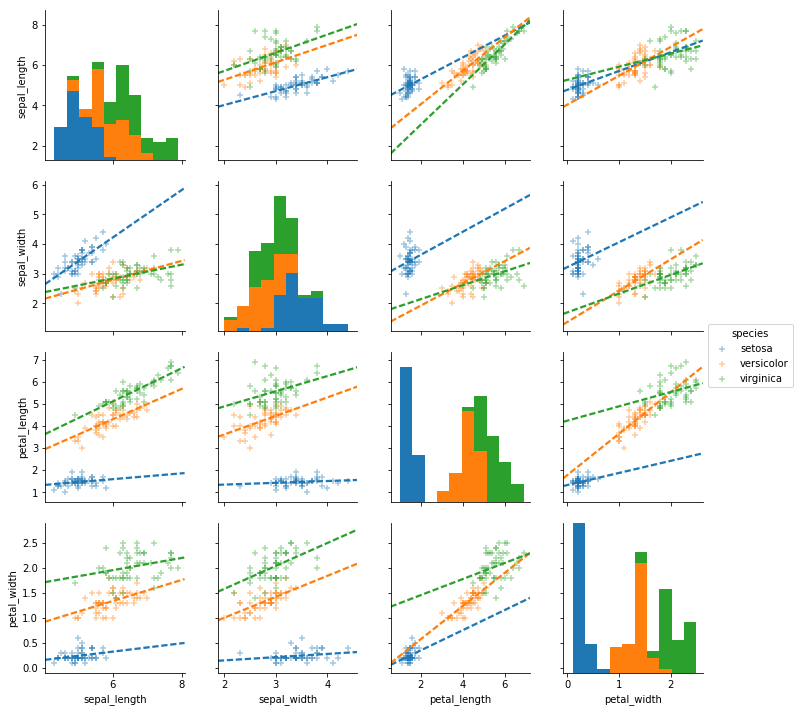
回帰直線を重ねてプロット: 引数kind
引数kind='reg'とすると散布図に線形回帰の回帰直線が重ねてプロットされる。
sns.pairplot(df, hue='species', kind='reg').savefig('data/dst/seaborn_pairplot_kind_reg.png')
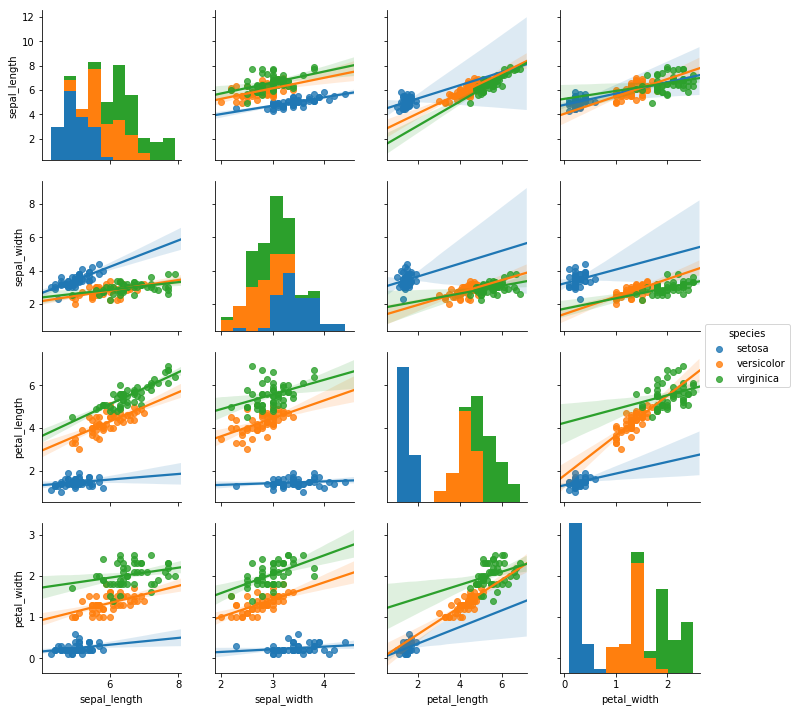
なお、pandas.DataFrameのcorr()メソッドで相関係数を算出することもできる。以下の記事を参照。
対角線のグラフの種類をカーネル密度推定に変更: 引数diag_kind
引数diag_kind='kde'とすると対角線のグラフの種類をヒストグラムからカーネル密度推定に変更できる。
sns.pairplot(df, hue='species', diag_kind='kde').savefig('data/dst/seaborn_pairplot_diag_kind_kde.png')
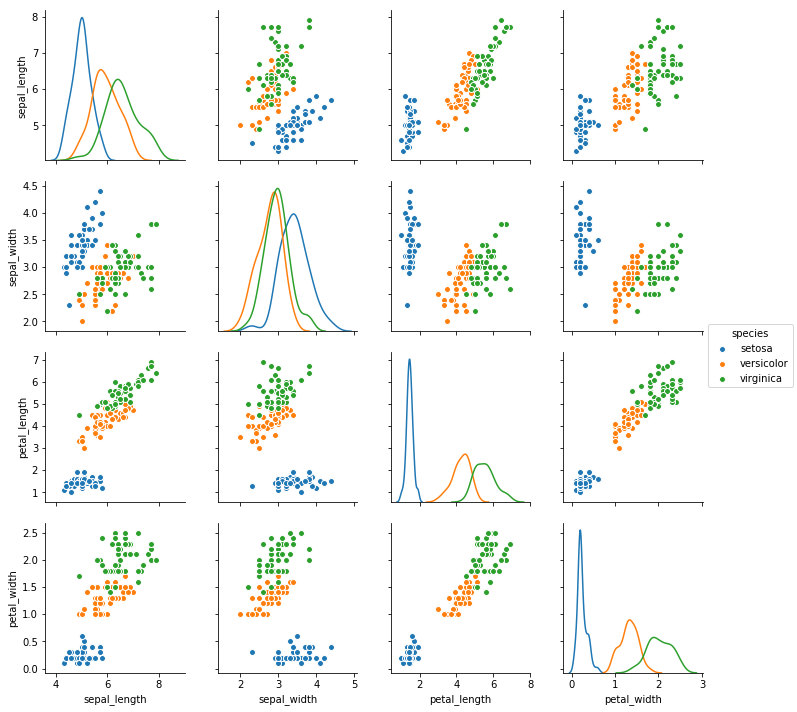
seabornのバージョン0.8.0まで引数hueとpaletteを設定してもカーネル密度推定のグラフが色分けされないというバグがあった。0.8.1ではFixされている。
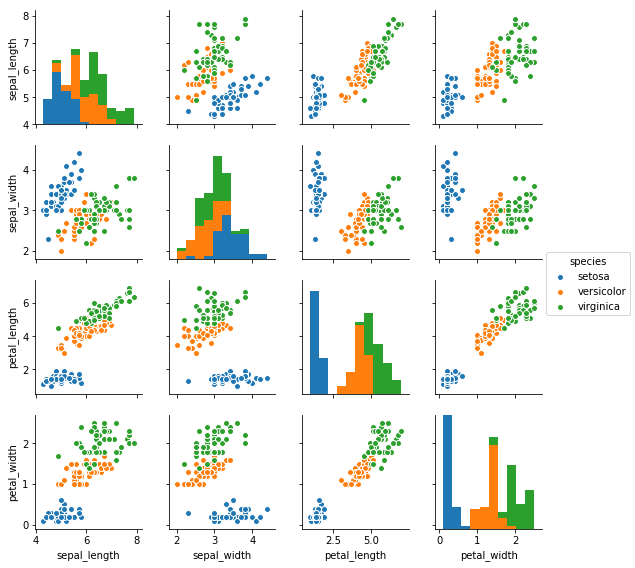
サイズを指定: 引数size
出力されるグラフのサイズは引数sizeで調整できる。単位はインチ。
sns.pairplot(df, hue='species', size=2).savefig('data/dst/seaborn_pairplot_size.png')
その他の引数: 引数plot_kws, diag_kws
散布図、ヒストグラムに対してpairplot()に用意されている以外の細かい引数は、それぞれ引数plot_kws, diag_kwsで指定できる。
Matplotlibのscatter(), hist()の引数を辞書形式で指定する。
- matplotlib.pyplot.scatter — Matplotlib 2.2.2 documentation
- matplotlib.pyplot.hist — Matplotlib 2.2.2 documentation
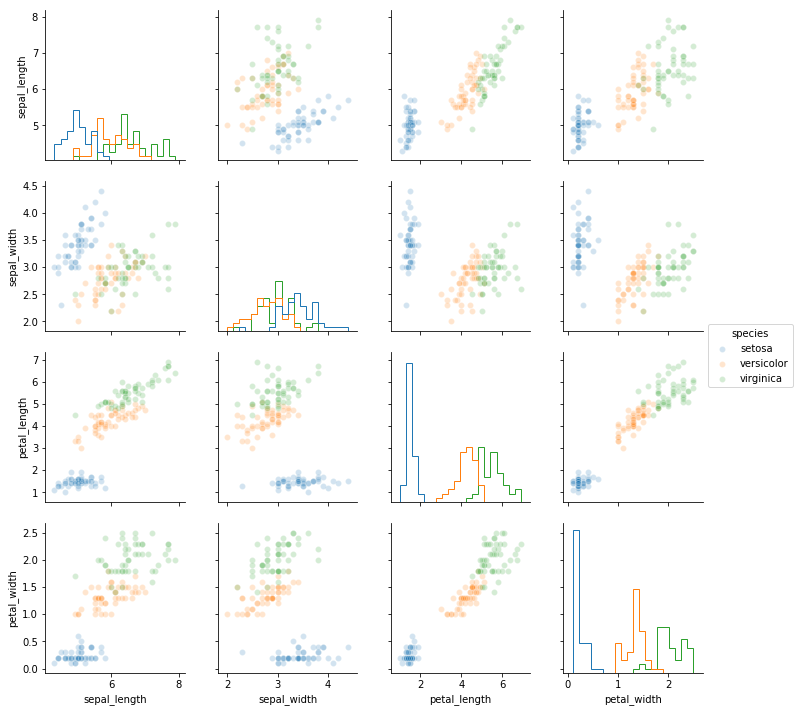
散布図の引数alphaで透過率を指定したり、ヒストグラムの引数binsで分割数、histtypeでタイプを指定できる。
sns.pairplot(df, hue='species',
plot_kws={'alpha': 0.2},
diag_kws={'bins': 20, 'histtype': 'step'}).savefig('data/dst/seaborn_pairplot_kws.png')
引数kind='reg'として回帰直線をプロットする場合はplot_kwsにseaborn.regplot()の引数を指定できる。
sns.pairplot(df, hue='species', kind='reg',
plot_kws={'ci': None,
'marker': '+',
'scatter_kws': {'alpha': 0.4},
'line_kws': {'linestyle': '--'}}).savefig('data/dst/seaborn_pairplot_kind_reg_kws.png')