TensorFlow, Kerasの基本的な使い方(モデル構築・訓練・評価・予測)
TensorFlow(主に2.0以降)とそれに統合されたKerasを使って、機械学習・ディープラーニングのモデル(ネットワーク)を構築し、訓練(学習)・評価・予測(推論)を行う基本的な流れを説明する。
- 公式ドキュメント(チュートリアルとAPIリファレンス)
- TensorFlow 2.0(TF2)でモデルを構築する3つの方法
- データの読み込み(MNIST手書き数字データ)
- Sequential APIによるモデルの構築
- 訓練(学習)プロセスの設定:
Model.compile() - 訓練の実行:
Model.fit() - 学習済みモデルの評価:
Model.evaluate() - 学習済みモデルを使った予測(推論):
Model.predict() - 学習済みモデルの保存と復元:
Model.save() - Functional APIによるモデル構築
- Subclassing API(Model Subclassing)によるモデル構築
- (参考)カスタムトレーニングループ
本記事のサンプルコードでのTensorFlowのバージョンは2.1.0。TensorFlowに統合されたKerasを使う。
スタンドアローンのKerasを使う場合、import kerasで別途Kerasをインポートして、コード中のtf.kerasの部分をkerasに置き換えれば動くかもしれないが、保証はできない。
訓練(training)と学習(learning)、予測(prediction)と推論(inference)など、用語の使い分けは適当。厳密な定義に則っているわけではなのでご了承ください。
公式ドキュメント(チュートリアルとAPIリファレンス)
TensorFlow
TensorFlowの公式サイトは以下。
チュートリアルが充実しているので、まずはざっとでも眺めてみるとよい。サイドバー(モバイルの場合はハンバーガーメニュー)に様々なトピックへのリンクがある。
バージョンごとのAPIリファレンスは以下。
Keras
Kerasの公式サイト(公式ドキュメント)は以下。
2020年3月時点では、日本語版を含む翻訳版はサイドバーが英語版のように展開されていない。トピックの一覧を確認するのは英語版のほうが便利。また、翻訳版の内容は最新でない場合もあるので、英語版にも目を通しておくといい。
英語版と日本語版のURLは以下のようになっている。jaの有無で切り替えられる。
https://keras.io/xxxxx/
https://keras.io/ja/xxxxx/
Kerasの公式ドキュメントにおけるサンプルコードはスタンドアローンのKerasを使ったもの。TensorFlowに組み込まれたKerasを使う場合はインポートの部分を例えば以下のように書き換える。
from keras.models import Sequential
=>
from tensorflow.keras.models import Sequential
先にimport tensorflow as tfのように略称(tf)でインポートしていても、fromやimportでは正式名称(tensorflow)を使う必要があるので注意。
NG
import tensorflow as tf
from tf.keras.models import Sequential
# ModuleNotFoundError: No module named 'tf'
OK
import tensorflow as tf
from tensorflow.keras.models import Sequential
なお、バージョンの違いなどの理由によって、すべてのサンプルコードがインポートを変えるだけで動作するとは限らない。
TensorFlow 2.0(TF2)でモデルを構築する3つの方法
TensorFlow 2.0以降(TF2)ではモデルを構築する方法が3つある。
- Sequential API
- シンプルな一直線のモデルを構築可能
- Functional API
- 複数の入出力を持つモデルやレイヤーを共有するモデルなども構築可能
- Subclassing API (Model Subclassing)
- 最も柔軟にモデルを構築可能
- PyTorchに似た書き方
概要の説明は以下の公式ブログを参照。
- Google Developers Japan: TensorFlow 2.0 のシンボリック API と命令型 API とは?
- What are Symbolic and Imperative APIs in TensorFlow 2.0?
公式ブログ記事では以下のように分類されている。
- シンボリック(宣言型)API
- Sequential API
- Functional API
- 命令型(モデル サブクラス化)API
- Subclassing API (Model Subclassing)
ここからは、まず、データの読み込みからモデルの構築・訓練・評価・予測までの一連の流れをSequential APIを使ったサンプルコードで説明し、そのあとでFunctional APIとSubclassing APIによるモデル構築のサンプルコードを示す。
冒頭にも書いたように、以下のサンプルコードでのTensorFlowのバージョンは2.1.0。TensorFlowに統合されたKerasを使う。
import tensorflow as tf
import numpy as np
from PIL import Image
print(tf.__version__)
# 2.1.0
tf.random.set_seed(0)
スタンドアローンのKerasを使う場合、import kerasで別途Kerasをインポートして、コード中のtf.kerasの部分をkerasに置き換えれば動くかもしれないが、保証はできない。
ここでは、実行のたびに同じ結果となるようにtf.random.set_seed()でランダムシードを固定している。環境や使用する機能によってはこれだけだと不十分な場合もあるので注意。
コード全体は以下。
- tf_keras_sequential_verbose.ipynb · nkmk/tensorflow-keras-examples
- シンプル版: tf_keras_sequential.ipynb · nkmk/tensorflow-keras-examples
データの読み込み(MNIST手書き数字データ)
例としてMNIST手書き文字(数字)データを使う。
tf.keras.datasets.mnist.load_data()で読み込む。最初に実行したときに~/.keras/datasetにデータがダウンロードされる。
訓練データとテストデータがあり、それぞれに画像とラベル(正解)が含まれている。
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
データはNumPy配列ndarrayとして読み込まれる。
画像のサイズは28 x 28で、uint8(0 - 255)のグレースケール。訓練データは60000枚。
print(type(x_train))
# <class 'numpy.ndarray'>
print(x_train.shape)
# (60000, 28, 28)
print(x_train.dtype)
# uint8
print(x_train.min(), '-', x_train.max())
# 0 - 255
画像ファイルとして保存すると、どういう内容か確認できる。ここでは見やすくするため拡大して保存している。
Image.fromarray(x_train[0]).resize((256, 256)).save('../data/img/dst/mnist_sample_resize.png')
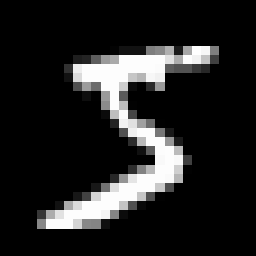
テストデータは10000枚。
print(x_test.shape)
# (10000, 28, 28)
画像に対応する正解ラベルには0から9までの数値が格納されている。
print(type(y_train))
# <class 'numpy.ndarray'>
print(y_train.shape)
# (60000,)
print(y_train.dtype)
# uint8
print(y_train.min(), '-', y_train.max())
# 0 - 9
print(np.unique(y_train))
# [0 1 2 3 4 5 6 7 8 9]
上で最初の画像をファイルとして保存して示したが、その画像に対応するラベルは以下の通り。3にも見えなくはないが、正解は5だということが分かる。
print(y_train[0])
# 5
テストデータも同様に10000枚分の正解ラベルが格納されている。
print(y_test.shape)
# (10000,)
前処理として、画像を最大値255で割って0.0 - 1.0に規格化する。
x_train = x_train / 255
x_test = x_test / 255
print(x_train.dtype)
# float64
print(x_train.min(), '-', x_train.max())
# 0.0 - 1.0
割り算によって自動的にfloat64にキャスト(型変換)される。
環境や実装によってはfloat32にしておかないとモデルの訓練時などにエラーや警告が出ることがある。そのような場合は明示的にastype('float32')でキャストすればよい。
なお、ここではtf.keras.datasets.mnist.load_data()を使ったが、最終的に同じ形状shapeのnumpy.ndarrayであれば、どうやって読み込んでも問題ない。
メモリに乗り切らない大量の画像を扱いたい場合はImageDataGeneratorのflow_from_directory()やflow_from_dataframe()を使ってファイルを逐次読み込む方法がある。
ImageDataGeneratorの具体例は以下のチュートリアルを参照。
Sequential APIによるモデルの構築
Sequential APIでモデルを構築するにはtf.keras.Sequential()を使う。
上記ドキュメントのView aliasesをクリックすると分かるように、tf.keras.models.Sequentialはtf.keras.Sequentialのエイリアス。どちらを使ってもよい。
print(tf.keras.Sequential is tf.keras.models.Sequential)
# True
レイヤーのリストを指定する方法と、add()で順にレイヤーを追加していく方法がある。レイヤーの種類は以下を参照。
なお、モデルの層構成は以下の公式チュートリアルに準じた。ここではどのようなレイヤーを選択すると精度が向上するかといった内容には踏み込まない。
レイヤーのリストを指定
レイヤーを入力層から順番に並べたリストを指定する。summary()でモデルの構造を確認できる。
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28), name='flatten_layer'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
], name='my_model')
model.summary()
# Model: "my_model"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_layer (Flatten) (None, 784) 0
# _________________________________________________________________
# dense (Dense) (None, 128) 100480
# _________________________________________________________________
# dropout (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_1 (Dense) (None, 10) 1290
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
上の例のように、引数nameでモデル全体および各レイヤーに任意の名前を付けることができる。nameの指定は必須ではなく、省略した場合は自動的に名前が付けられる。
例の全結合層Denseでは引数activationで活性化関数を指定している。以下のように個別のレイヤーとして扱うこともできる。
...
tf.keras.layers.Dense(128, activation='relu'),
...
=>
...
tf.keras.layers.Dense(128),
tf.keras.layers.ReLU(),
...
add()で順にレイヤーを追加
空のモデルを生成したあとでadd()で順にレイヤーを追加する方法もある。
model_1 = tf.keras.Sequential(name='my_model_1')
model_1.add(tf.keras.layers.Flatten(input_shape=(28, 28), name='flatten_layer_1'))
model_1.add(tf.keras.layers.Dense(128, activation='relu'))
model_1.add(tf.keras.layers.Dropout(0.2))
model_1.add(tf.keras.layers.Dense(10, activation='softmax'))
model_1.summary()
# Model: "my_model_1"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_layer_1 (Flatten) (None, 784) 0
# _________________________________________________________________
# dense_2 (Dense) (None, 128) 100480
# _________________________________________________________________
# dropout_1 (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_3 (Dense) (None, 10) 1290
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
インポートによる違い
サンプルコードによってはクラスなどを直接インポートしているものもある。
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
model_2 = Sequential([
Flatten(input_shape=(28, 28), name='flatten_layer_2'),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
], name='my_model_2')
model_2.summary()
# Model: "my_model_2"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_layer_2 (Flatten) (None, 784) 0
# _________________________________________________________________
# dense_4 (Dense) (None, 128) 100480
# _________________________________________________________________
# dropout_2 (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_5 (Dense) (None, 10) 1290
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
ただ単にインポート方法が違っているだけで、当然ながらこれらのクラスは同じもの。
print(tf.keras.Sequential is Sequential)
# True
モジュールを別名でインポートする例もある。
import tensorflow.keras.layers as L
print(tf.keras.layers.Dense is L.Dense)
# True
importについての詳細は以下の記事を参照。
訓練(学習)プロセスの設定: Model.compile()
生成したモデルに訓練(学習)プロセスを設定するにはcompile()を使う。
compile()の引数optimizer, loss, metricsにそれぞれ最適化アルゴリズム、損失関数、評価関数を指定する。metricsにはリストまたは辞書を指定する必要がある。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
上の例のように名前を文字列で指定するほか、各クラスのインスタンスを生成して指定することもできる。
名前を文字列で指定する場合はデフォルトパラメータが使用されるが、クラスのインスタンスを指定する場合はオプティマイザーの学習率learning_rateなどのパラメータを引数で設定可能。上のモデルはあとで使うため、別のモデルで例を示す。
model_1.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
ちなみに、学習率は引数lrでも指定可能だが、これは後方互換のためなのでlearning_rateを使うことが推奨されている。
lr is included for backward compatibility, recommended to use learning_rate instead. tf.keras.optimizers.Adam - args | TensorFlow Core v2.1.0
なお、文字列'accuracy'や'acc'で指定した場合は損失関数から適切な評価関数が選ばれるが、インスタンスを指定する場合は自分で正しく選ばなければいけない。要注意。
それぞれの一覧は以下の公式ドキュメントを参照。
- 最適化アルゴリズム
- 損失関数
- 評価関数
損失関数tf.keras.losses, 評価関数tf.keras.metricsモジュールではクラスだけでなく関数も提供されている。
- tf.keras.metrics.SparseCategoricalAccuracy | TensorFlow Core v2.1.0
- tf.keras.metrics.sparse_categorical_accuracy | TensorFlow Core v2.1.0
キャメルケースXxxYyyZzzがクラスで、スネークケースxxx_yyy_zzzが関数。
compile()の引数loss, metricsには関数オブジェクトを直接指定できる。関数オブジェクトの指定なので()は不要。ここでは上記のモジュールで定義されている関数を使っているが、独自の関数を定義して指定することも可能。
model_1.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy])
訓練の実行: Model.fit()
訓練の実行はfit()。引数でバッチサイズやエポック数などを指定する。バリデーションやコールバックについては後述。
callbacks = [tf.keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True),
tf.keras.callbacks.ModelCheckpoint(
'../data/temp/mnist_sequential_{epoch:03d}_{val_loss:.4f}.h5',
save_best_only=True
)]
history = model.fit(x_train, y_train, batch_size=128, epochs=20,
validation_split=0.2, callbacks=callbacks)
# Train on 48000 samples, validate on 12000 samples
# Epoch 1/20
# 48000/48000 [==============================] - 1s 29us/sample - loss: 0.4443 - accuracy: 0.8751 - val_loss: 0.2079 - val_accuracy: 0.9427
# Epoch 2/20
# 48000/48000 [==============================] - 1s 22us/sample - loss: 0.2112 - accuracy: 0.9393 - val_loss: 0.1507 - val_accuracy: 0.9584
# Epoch 3/20
# 48000/48000 [==============================] - 1s 23us/sample - loss: 0.1590 - accuracy: 0.9540 - val_loss: 0.1238 - val_accuracy: 0.9647
# Epoch 4/20
# 48000/48000 [==============================] - 1s 23us/sample - loss: 0.1302 - accuracy: 0.9616 - val_loss: 0.1083 - val_accuracy: 0.9679
# Epoch 5/20
# 48000/48000 [==============================] - 1s 22us/sample - loss: 0.1111 - accuracy: 0.9671 - val_loss: 0.0992 - val_accuracy: 0.9709
# Epoch 6/20
# 48000/48000 [==============================] - 1s 23us/sample - loss: 0.0960 - accuracy: 0.9710 - val_loss: 0.0927 - val_accuracy: 0.9719
# Epoch 7/20
# 48000/48000 [==============================] - 1s 24us/sample - loss: 0.0855 - accuracy: 0.9742 - val_loss: 0.0880 - val_accuracy: 0.9732
# Epoch 8/20
# 48000/48000 [==============================] - 1s 23us/sample - loss: 0.0748 - accuracy: 0.9772 - val_loss: 0.0809 - val_accuracy: 0.9760
# Epoch 9/20
# 48000/48000 [==============================] - 1s 24us/sample - loss: 0.0691 - accuracy: 0.9787 - val_loss: 0.0819 - val_accuracy: 0.9743
# Epoch 10/20
# 48000/48000 [==============================] - 1s 23us/sample - loss: 0.0630 - accuracy: 0.9808 - val_loss: 0.0771 - val_accuracy: 0.9758
# Epoch 11/20
# 48000/48000 [==============================] - 1s 22us/sample - loss: 0.0569 - accuracy: 0.9831 - val_loss: 0.0801 - val_accuracy: 0.9753
# Epoch 12/20
# 48000/48000 [==============================] - 1s 22us/sample - loss: 0.0518 - accuracy: 0.9844 - val_loss: 0.0778 - val_accuracy: 0.9754
この例ではエポック数を20に指定しているが、コールバックでEarlyStoppingを指定しているため途中で終了している。
表示出力モードの指定: 引数verbose
表示される出力のモードは引数verboseで指定する。
デフォルトはverbose=1で、上の例のようにエポックごとのログがプログレスバーの進行状況とともに示される。verbose=2はプログレスバーなし(エポックごとのログはあり)、verbose=0は出力が一切なしになる。
返り値: History
fit()はtf.keras.callbacks.Historyオブジェクトを返す。
Historyのhistory属性にはlossやaccuracyなど訓練結果を含む辞書が格納されている。キーの名前はcompile()の設定によって変わる。
print(type(history))
# <class 'tensorflow.python.keras.callbacks.History'>
print(type(history.history))
# <class 'dict'>
print(history.history.keys())
# dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
print(history.history['accuracy'])
# [0.87514585, 0.93927085, 0.9539792, 0.96164584, 0.967125, 0.9710417, 0.9741875, 0.9771875, 0.97866666, 0.98075, 0.98310417, 0.98441666]
特に結果を取得する必要がない場合は、history = model.fit(...)とせずに、ただmodel.fit(...)としてももちろん構わない。
バリデーション
fit()の引数validation_splitで訓練データとバリデーションデータを分割できる。例えばvalidation_split=0.2の場合はデータの末尾20%がバリデーション(検証)に使われる。デフォルトはvalidation_split=0.0で、すべてのデータが訓練に使われる。
第一引数xがnumpy.ndarrayではなくジェネレーターの場合(ImageDataGeneratorを使うときなど)はvalidation_splitは使えない。
The validation data is selected from the last samples in the x and y data provided, before shuffling. This argument is not supported when x is a dataset, generator or keras.utils.Sequence instance. tf.keras.Model.fit() | TensorFlow Core v2.1.0
ジェネレーターを使う場合や、元のデータを分割するのではなく別のデータを指定したい場合は、引数validation_dataを使う。
コールバック
訓練中(エポック終了時など)に呼び出したい関数を引数callbacksにリストで指定する。
上の例では、改善が見られなくなった時点で訓練を終了するEarlyStoppingと、エポック終了時にモデルを保存するModelCheckpointを指定している。
- tf.keras.callbacks.EarlyStopping | TensorFlow Core v2.1.0
- tf.keras.callbacks.ModelCheckpoint | TensorFlow Core v2.1.0
EarlyStoppingではrestore_best_weights=Trueとしないとベスト時ではなく最終時の重さが保持されるので注意(デフォルトはrestore_best_weights=False)。
ModelCheckpointで保存したモデルデータからの復元については後述。
そのほかの設定などは上記のドキュメントを参照されたい。
上の2つのほかにも様々なコールバックが提供されており、カスタムコールバックを生成することもできる。
- Module: tf.keras.callbacks | TensorFlow Core v2.1.0
- コールバック - Keras Documentation
- Keras custom callbacks | TensorFlow Core
訓練の結果を可視化するTensorBoardのためのログの保存もコールバックを設定して行う。
学習済みモデルの評価: Model.evaluate()
訓練したモデルを評価するにはevaluate()を使う。
テストデータを指定するとcompile()で指定した損失関数loss、評価関数metricsの結果が返される。
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(test_loss)
# 0.07156232252293267
print(test_acc)
# 0.9786
学習済みモデルを使った予測(推論): Model.predict()
訓練したモデルで実際に予測(推論)を行うにはpredict()を使う。
モデルの妥当性・性能を確認するにはevaluate()を使い、個別のサンプルのデータに対してどのような値を予測するかを確認するにはpredict()を使う。
テストデータ全体を予測
テストデータの画像データを引数に指定するとnumpy.ndarrayが返される。
print(x_test.shape)
# (10000, 28, 28)
predictions = model.predict(x_test)
print(type(predictions))
# <class 'numpy.ndarray'>
print(predictions.shape)
# (10000, 10)
最初のサンプルの結果は以下の通り。
それぞれの値が確率を示しており([0である確率, 1である確率, 2である確率, ... , 9である確率])、すべての確率を合計すると1になる。これは、今回のモデルで出力層の活性化関数として使用したソフトマックス関数の性質。
print(predictions[0])
# [3.22501933e-06 1.48081245e-08 2.89624350e-05 3.07988637e-04
# 2.93199742e-10 3.28161093e-07 2.59668814e-11 9.99620199e-01
# 5.64465245e-06 3.35659788e-05]
print(predictions[0].sum())
# 0.99999994
最大値のインデックスはargmax()で取得できる。この例ではテストデータの最初の画像は7である確率が最も高いと予測されていることが分かる。
print(predictions[0].argmax())
# 7
argmax()の引数axisを指定して、全サンプルの予測結果をまとめて取得することも可能。
results = predictions.argmax(axis=1)
print(results)
# [7 2 1 ... 4 5 6]
print(type(results))
# <class 'numpy.ndarray'>
print(results.shape)
# (10000,)
任意の画像を予測
任意の画像を読み込んで予測することもできる。
上で保存した画像(正解は5)をnumpy.ndarrayとして読み込み、画像サイズを(28, 28)に合わせて、255で割って0.0 ~ 1.0に規格化する。
img = np.array(Image.open('../data/img/dst/mnist_sample_resize.png').resize((28, 28))) / 255
print(img.shape)
# (28, 28)
が、このままpredict()に渡すとエラーになる。
# predictions_single = model.predict(img)
# ValueError: Error when checking input: expected flatten_input to have 3 dimensions, but got array with shape (28, 28)
これは、TensorFlow, Kerasではバッチ処理を前提としているため。上の例のテストデータ10000枚の画像全体の形状が(10000, 28, 28)であるように、1枚でも(28, 28)ではなく(1, 28, 28)としなければならない。
img_expand = img[np.newaxis, ...]
print(img_expand.shape)
# (1, 28, 28)
numpy.ndarrayに大きさ1の新たな次元を追加するにはnp.newaxisやNoneを使う方法や、np.expand_dims()を使う方法がある。
tf.newaxisもnp.newaxisと同様に使える。
print(img[None, ...].shape)
# (1, 28, 28)
print(np.expand_dims(img, 0).shape)
# (1, 28, 28)
print(tf.newaxis)
# None
print(img[tf.newaxis, ...].shape)
# (1, 28, 28)
np.newaxisやtf.newaxis, Noneで先頭に次元を追加する場合、末尾の...や:は省略可能。お好みで。
print(img[np.newaxis].shape)
# (1, 28, 28)
予測した結果は以下の通り。正しく5と分類できている。結果の形状も(10, )ではなく(1, 10)なので注意。
predictions_single = model.predict(img_expand)
print(predictions_single)
# [[6.8237398e-09 1.0004978e-08 4.0168429e-06 4.5704491e-02 2.8772252e-14
# 9.5429057e-01 5.5912805e-12 3.1738683e-08 6.9545142e-10 9.2607473e-07]]
print(predictions_single.shape)
# (1, 10)
print(predictions_single[0].argmax())
# 5
学習済みモデルの保存と復元: Model.save()
モデルの構造および学習した重みはsave()で保存できる。
第一引数に保存先のパスを指定する。
model.save('../data/temp/my_model.h5')
保存したファイルはtf.keras.models.load_model()で読み込んで、モデルおよび重みを復元できる。
evaluate()やpredict()を実行すると保存する前と同じ結果が得られることが確認できる。
new_model = tf.keras.models.load_model('../data/temp/my_model.h5')
new_model.summary()
# Model: "my_model"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_layer (Flatten) (None, 784) 0
# _________________________________________________________________
# dense (Dense) (None, 128) 100480
# _________________________________________________________________
# dropout (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_1 (Dense) (None, 10) 1290
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
print(new_model.evaluate(x_test, y_test, verbose=0))
# [0.07156232252293267, 0.9786]
print(new_model.predict(img_expand))
# [[6.8237398e-09 1.0004978e-08 4.0168429e-06 4.5704491e-02 2.8772252e-14
# 9.5429057e-01 5.5912805e-12 3.1738683e-08 6.9545142e-10 9.2607473e-07]]
上述のコールバックtf.keras.callbacks.ModelCheckpoint()で保存されたHDF5ファイルもtf.keras.models.load_model()で読み込み可能。
HDF5形式のほか、TensorFlowのSavedModel形式での保存もできる。SavedModelの場合は単一のファイルではなくディレクトリとして保存される。読み込む場合はディレクトリのパスをtf.keras.models.load_model()に指定すればよい。
save()の第一引数に指定するパスの拡張子をh5またはhdf5とするとHDF5形式で保存されるが、それ以外(拡張子を付けない場合など)は引数save_formatによってどちらの形式で保存されるかが決まる。save_formatのデフォルト値がTF2系とTF1系で異なるので注意。
save_format: Either 'tf' or 'h5', indicating whether to save the model to Tensorflow SavedModel or HDF5. Defaults to 'tf' in TF 2.X, and 'h5' in TF 1.X. tf.keras.Model.save() | TensorFlow Core v2.1.0
そのほか、モデルの構造のみを保存・復元するto_json(), to_yaml(), model_from_json(), model_from_yaml()や、
重みのみを保存・復元するsave_weights(), load_weights()もある。
詳細は公式ドキュメントを参照。
- Save and serialize models with Keras | TensorFlow Core
- モデルの保存と復元 | TensorFlow Core
- FAQ - Keras modelを保存するには? - Keras Documentation
自分で保存したモデルおよびその重みではなく、Kerasが提供するVGG16などの有名なモデルと学習済みの重みを使用することもできる。以下の記事を参照。
Functional APIによるモデル構築
ここまでのSequential APIの例と同様のモデルはFunctional APIでは以下のように書ける。
inputs = tf.keras.Input(shape=(28, 28))
x = tf.keras.layers.Flatten()(inputs)
x = tf.keras.layers.Dense(128, activation='relu')(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = tf.keras.layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
入力と出力を関数の形で記述して、tf.keras.Model()の引数inputsとoutputsに指定する。
tf.keras.models.Modelはtf.keras.Modelのエイリアス。どちらを使ってもよい。
print(tf.keras.Model is tf.keras.models.Model)
# True
最後に括弧が続いているのは奇妙に見えるかもしれないが、以下のような2つの処理を続けて書いているだけ。
flatten = tf.keras.layers.Flatten()
x = flatten(inputs)
x = tf.keras.layers.Flatten()(inputs)
上のSequential APIの例と同様にcompile()やfit(), evaluate()などを行うと同じ結果が得られる。
print(model.evaluate(x_test, y_test, verbose=0))
# [0.07156232252293267, 0.9786]
コード全体は以下のリンクから。
ここでは基本的な説明のためSequential APIでも構築可能な一直線のモデルを例としたが、本来のFunctional APIのメリットは複数の入出力を持つモデルやレイヤーを共有するモデルなどを構築できる点にある。
そのような複雑なモデルの例は以下の公式ドキュメントを参照。
Subclassing API(Model Subclassing)によるモデル構築
ここまでのSequential API, Functional APIの例と同様のモデルをSubclassing API(Model Subclassing)で書くと以下のようになる。
class MyModel(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.flatten = tf.keras.layers.Flatten()
self.fc1 = tf.keras.layers.Dense(128, activation='relu')
self.fc2 = tf.keras.layers.Dense(10, activation='softmax')
self.dropout = tf.keras.layers.Dropout(0.2)
def call(self, x, training=False):
x = self.flatten(x)
x = self.fc1(x)
x = self.dropout(x, training=training)
x = self.fc2(x)
return x
model = MyModel()
tf.keras.Modelを継承して新たなモデルを作る、PyTorchに似た書き方。__init__でレイヤーを定義しておいて、callでFunctional APIのようにモデルを定義する。
By subclassing the Model class: in that case, you should define your layers in
__init__and you should implement the model's forward pass incall. tf.keras.Model | TensorFlow Core v2.1.0
生成したインスタンスからcompile()やfit()を呼ぶとSequential API, Functional APIと同じ結果が得られる。
print(model.evaluate(x_test, y_test, verbose=0))
# [0.07156232252293267, 0.9786]
コード全体は以下のリンクから。
Dropout層やBatchNormalization層などの訓練時とそれ以外で異なる振る舞いをするレイヤーに対しては、引数trainingを渡すことで動作を制御できる。
If you subclass Model, you can optionally have a training argument (boolean) in call, which you can use to specify a different behavior in training and inference: tf.keras.Model | TensorFlow Core v2.1.0
- tf.keras.layers.Dropout | TensorFlow Core v2.1.0
- tf.keras.layers.BatchNormalization | TensorFlow Core v2.1.0
fit()やpredict()などのメソッドでは自動的に指定され使い分けられるようだが、次に紹介するようなトレーニングループも自分で実装する場合は明示的に指定する必要があるので注意。
Subclassing APIについての公式ドキュメントは以下。
- Writing custom layers and models with Keras | TensorFlow Core
- エキスパートのための TensorFlow 2.0 入門 | TensorFlow Core
- モデルについて - モデルの派生(Model subclassing) - Keras Documentation
- About Keras models - Model subclassing - Keras Documentation
Subclassing APIの制限
Kerasのチュートリアルにもあるように、Subclassing APIで生成したモデルはto_json()やto_yaml()が使えないといった制約がある。
In subclassed models, the model's topology is defined as Python code (rather than as a static graph of layers). That means the model's topology cannot be inspected or serialized. About Keras models - Model subclassing - Keras Documentation
なお、save()ではHDF5形式での保存はできないが、SavedModel形式での保存は可能。
Models built with the Sequential and Functional API can be saved to both the HDF5 and SavedModel formats. Subclassed models can only be saved with the SavedModel format. tf.keras.Model.save() | TensorFlow Core v2.1.0
そのほか、Subclassing APIで生成したモデルは「Define by Run」形式なので、fit()で実際にデータを流して訓練するか、build()で入力形状を指定してモデルを確定する前はsummary()で構成を出力できないという制約もある。
fit()の前にsummary()を呼ぶと、以下のようにエラーとなる。
# model.summary()
# ValueError: This model has not yet been built. Build the model first by calling `build()`
# or calling `fit()` with some data, or specify an `input_shape` argument in the first layer(s) for automatic build.
fit()の後にsummary()を実行した例は以下。
model.summary()
# Model: "my_model"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten (Flatten) multiple 0
# _________________________________________________________________
# dense (Dense) multiple 100480
# _________________________________________________________________
# dense_1 (Dense) multiple 1290
# _________________________________________________________________
# dropout (Dropout) multiple 0
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
出力はされているが、レイヤーの順番がcallで定義した順ではなく__init__で定義した順になっていることやOutput Shapeがすべてmultipleになっていることに注意。Sequential APIやFunctional APIのモデルのように細かい情報まで出力できない。
build()では引数に入力の形状shapeをタプルで指定する。
上の例のfit()と同様の形状を指定すると以下の通り。バッチの次元(最初の次元)も必要なので注意。ここではNoneとしている。
model = MyModel()
model.build((None, 28, 28))
model.summary()
# Model: "my_model_1"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_1 (Flatten) multiple 0
# _________________________________________________________________
# dense_2 (Dense) multiple 100480
# _________________________________________________________________
# dense_3 (Dense) multiple 1290
# _________________________________________________________________
# dropout_1 (Dropout) multiple 0
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________
一度fit()やbuild()で構築されたモデルを別の入力形状で再構築することはできずエラーとなる。新たなインスタンスを生成する必要がある。
# model.build((None, 100, 100))
# ValueError: Input 0 of layer dense_2 is incompatible with the layer: expected axis -1 of input shape to have value 784 but received input with shape [None, 10000]
別の形状を指定すると、Paramの値がその形状に応じて変わっていることが確認できる。
model = MyModel()
model.build((None, 100, 100))
model.summary()
# Model: "my_model_2"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# flatten_2 (Flatten) multiple 0
# _________________________________________________________________
# dense_4 (Dense) multiple 1280128
# _________________________________________________________________
# dense_5 (Dense) multiple 1290
# _________________________________________________________________
# dropout_2 (Dropout) multiple 0
# =================================================================
# Total params: 1,281,418
# Trainable params: 1,281,418
# Non-trainable params: 0
# _________________________________________________________________
クラスの定義時に入力形状を固定する必要がなく、fit()やbuild()を実行することで入力形状に応じたモデルが構築される。
(参考)カスタムトレーニングループ
これまでの例はすべてfit()で訓練を行ってきたが、独自のトレーニングループを実装することもできる。
ここではその詳細を説明することはしないので、以下の公式ドキュメントを参照されたい。
参考までに、以下のチュートリアルに従って実装したサンプルコードを示しておく。
import tensorflow as tf
print(tf.__version__)
# 2.1.0
tf.random.set_seed(0)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train.astype('float32') / 255, x_test.astype('float32') / 255
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
class MyModel(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.flatten = tf.keras.layers.Flatten()
self.fc1 = tf.keras.layers.Dense(128, activation='relu')
self.fc2 = tf.keras.layers.Dense(10, activation='softmax')
self.dropout = tf.keras.layers.Dropout(0.2)
def call(self, x, training=False):
x = self.flatten(x)
x = self.fc1(x)
x = self.dropout(x, training=training)
x = self.fc2(x)
return x
model = MyModel()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images, training=True)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
@tf.function
def test_step(images, labels):
predictions = model(images, training=False)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result() * 100))
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
# Epoch 1, Loss: 0.29496467113494873, Accuracy: 91.46166229248047, Test Loss: 0.14592134952545166, Test Accuracy: 95.75
# Epoch 2, Loss: 0.1424490064382553, Accuracy: 95.7683334350586, Test Loss: 0.11153808981180191, Test Accuracy: 96.5
# Epoch 3, Loss: 0.1064126268029213, Accuracy: 96.76000213623047, Test Loss: 0.08371027559041977, Test Accuracy: 97.5999984741211
# Epoch 4, Loss: 0.08819350600242615, Accuracy: 97.28333282470703, Test Loss: 0.07508747279644012, Test Accuracy: 97.77999877929688
# Epoch 5, Loss: 0.07610776275396347, Accuracy: 97.54166412353516, Test Loss: 0.07976310700178146, Test Accuracy: 97.58999633789062