pandas.DataFrameの各列間の相関係数を算出、ヒートマップで可視化
pandas.DataFrameの各列の間の相関係数を算出するにはcorr()メソッドを使う。
ここでは、以下の内容について説明する。
pandas.DataFrame.corr()の基本的な使い方- データ型が数値型・ブール型の列が計算対象
- 欠損値
NaNは除外されて算出
- 相関係数の算出方法の指定: 引数
method - 相関係数をヒートマップで可視化: seaborn
以下のpandas.DataFrameを例とする。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.DataFrame({'A': range(5),
'B': [x**2 for x in range(5)],
'C': [x**3 for x in range(5)]})
print(df)
# A B C
# 0 0 0 0
# 1 1 1 1
# 2 2 4 8
# 3 3 9 27
# 4 4 16 64
pandas.DataFrame.corr()の基本的な使い方
pandas.DataFrameオブジェクトからcorr()メソッドを呼ぶと、各列の間の相関係数が算出される。
結果はpandas.DataFrameで返る。
df_corr = df.corr()
print(df_corr)
print(type(df_corr))
# A B C
# A 1.000000 0.958927 0.905882
# B 0.958927 1.000000 0.987130
# C 0.905882 0.987130 1.000000
# <class 'pandas.core.frame.DataFrame'>
データ型が数値型・ブール型の列が計算対象
説明のため文字列とブールの列を追加する。
df['D'] = list('abcde')
df['E'] = [True, False, True, True, False]
print(df)
# A B C D E
# 0 0 0 0 a True
# 1 1 1 1 b False
# 2 2 4 8 c True
# 3 3 9 27 d True
# 4 4 16 64 e False
print(df.dtypes)
# A int64
# B int64
# C int64
# D object
# E bool
# dtype: object
corr()メソッドではデータ型がobject(文字列)の列は除外され、数値(int, float)型およびbool型の列の間の相関係数が算出される。
bool型はTrueが1、Falseが0とみなされる。
df_corr = df.corr()
print(df_corr)
# A B C E
# A 1.000000 0.958927 0.905882 -0.288675
# B 0.958927 1.000000 0.987130 -0.346023
# C 0.905882 0.987130 1.000000 -0.424522
# E -0.288675 -0.346023 -0.424522 1.000000
欠損値NaNは除外されて算出
説明のため欠損値Nanを含むpandas.DataFrameオブジェクトを用意する。
df_nan = df.copy()
df_nan.iloc[[2, 3, 4], 1] = np.nan
print(df_nan)
# A B C D E
# 0 0 0.0 0 a True
# 1 1 1.0 1 b False
# 2 2 NaN 8 c True
# 3 3 NaN 27 d True
# 4 4 NaN 64 e False
corr()メソッドでは欠損値NaNは除外されて相関係数が算出される。
df_nan_corr = df_nan.corr()
print(df_nan_corr)
# A B C E
# A 1.000000 1.0 0.905882 -0.288675
# B 1.000000 1.0 1.000000 -1.000000
# C 0.905882 1.0 1.000000 -0.424522
# E -0.288675 -1.0 -0.424522 1.000000
相関係数の算出方法の指定: 引数method
corr()メソッドでは引数methodで相関係数の算出方法を指定できる。
以下の3種類から選択する。
'pearson': ピアソンの積率相関係数(デフォルト)'kendall': ケンドールの順位相関係数'spearman': スピアマンの順位相関係数
相関係数をヒートマップで可視化: seaborn
Pythonのビジュアライゼーションライブラリseabornを使うと、corr()で得られるようなpandas.DataFrameをヒートマップとして簡単に可視化できる。
seaborn.heatmap()関数を使う。引数などの詳細は以下の記事を参照。
sns.heatmap(df_corr, vmax=1, vmin=-1, center=0)
plt.savefig('data/dst/seaborn_heatmap_corr_example.png')

具体的な例として、Kaggleの住宅価格を推定する問題のトレーニングデータから相関係数を算出しヒートマップで可視化してみる。
データのcsvファイルはこちらにも置いてある。
元のデータは多数の列(特徴量)を持っているが、上述のように、corr()メソッドではデータ型dtypeがobjectの列は除外される。
df_house = pd.read_csv('data/src/house_prices_train.csv', index_col=0)
print(df_house.shape)
# (1460, 80)
print(df_house.dtypes.value_counts())
# object 43
# int64 34
# float64 3
# dtype: int64
df_house_corr = df_house.corr()
print(df_house_corr.shape)
# (37, 37)
seaborn.heatmap()関数で可視化。
fig, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(df_house_corr, square=True, vmax=1, vmin=-1, center=0)
plt.savefig('data/dst/seaborn_heatmap_house_price.png')
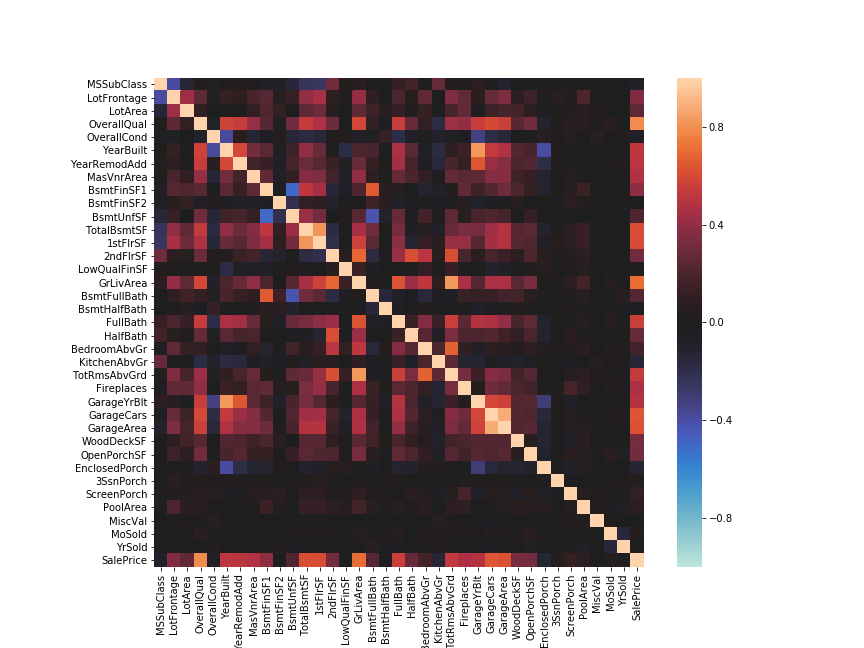
本来は欠損値NaNの補完や文字列(object型)のカテゴリー変数の数値化などの処理を行う必要があり、データをそのまま読み込んで使うのは乱暴ではあるが、機械学習の前処理段階などで各変数の関係性をとりあえずざっくり確認するのに非常に便利。