pandas-datareaderで株価や人口のデータを取得
pandas-datareaderを使うと、Web上の様々なソースに簡単にアクセスして、株価や為替レート、人口などのデータをpandas.DataFrameとして取得できる。
ここでは以下の内容について説明する。
pandas-datareaderの概要- インストール
- データソース
- 株価(Alpha Vantage)
- データ取得
- CSVで保存
- グラフをプロット
- 人口、GDPなど(World Bank)
- データ取得
- indicator
- 階層データの整形
以下のサンプルコードのpandas-datareaderのバージョンは0.8.1。2020年5月22日時点で動作を確認している。バージョンやデータソースの仕様が変わると動作しない可能性があるので注意。
pandas-datareaderの概要
インストール
以前はpandas.ioという名前でpandasの一部として提供されていたが、現在はpandas-datareaderとして独立している。
pip(環境によってはpip3)などで別途インストールする必要がある。
$ pip install pandas-datareader
GitHubから最新版をインストールすることも可能。
$ pip install git+https://github.com/pydata/pandas-datareader.git
データソース
公式ドキュメントによると、バージョン0.8.0時点では以下のデータソースがサポートされている。
- Tiingo
- IEX
- Alpha Vantage
- Enigma
- Quandl
- St.Louis FED (FRED)
- Kenneth French's data library
- World Bank
- OECD
- Eurostat
- Thrift Savings Plan
- Nasdaq Trader symbol definitions
- Stooq
- MOEX
以前は使えていたMorningstarが使えなくなっているなど変更も多いので、最新情報は以下のリンクを参照。
なお、Yahoo! Financeはバージョン0.6.0でDeprecatedになったあと0.7.0から再度サポートされているようだが、ドキュメントには反映されていない。確実な情報を知りたい場合はコードを読むしかないかもしれない。
また、データソース側の仕様変更によって動作しなくなる場合もある。エラー情報はGitHubのIssuesを参照。
株価(Alpha Vantage)
2020年5月22日時点ではTiingo, IEX, Alpha Vantageが使用可能だが、いずれもユーザー登録をしてAPIキーを取得する必要がある。
ここではAlpha Vantageの例を示す。
以下のフォームにEメールアドレスを記入するとAPIキーが取得できる。無料。
特にメールが送信されるわけではなく、ページ上にAPIキーが表示されるので忘れずに記録しておく。
2020年8月19日追記
上述のように公式ドキュメントには記載されていないが、2020年8月19日に確認したところYahoo! Financeも使用できた。次に説明するDataReader()の第二引数を'yahoo'とすればよい(APIキー不要)。
冒頭に述べたように、pandas-datareaderのバージョンやデータソース側の仕様変更によって対応状況は異なるので、最新情報はGitHubのレポジトリなどを確認されたい。
データ取得
例としてソニー(SNE)の株価情報を取得する。なお、取得できるのはニューヨーク証券取引所(NYSE)での株価で単位はドルとなる。
import datetime
import pandas as pd
import pandas_datareader.data as web
import matplotlib.pyplot as plt
with open('data/temp/alpha_vantage_api_key.txt') as f:
api_key = f.read()
start = datetime.datetime(2015, 1, 1)
end = datetime.datetime(2019, 12, 31)
df_sne = web.DataReader('SNE', 'av-daily', start, end, api_key=api_key)
print(df_sne)
# open high low close volume
# 2015-01-02 20.47 20.685 20.43 20.56 1229939
# 2015-01-05 20.45 20.450 20.21 20.26 1083137
# 2015-01-06 20.46 20.580 20.15 20.25 2209124
# 2015-01-07 21.59 21.700 21.47 21.53 2486293
# 2015-01-08 21.53 21.620 21.47 21.56 1296471
# ... ... ... ... ... ...
# 2019-12-24 67.98 68.000 67.76 67.76 264463
# 2019-12-26 68.00 68.030 67.85 68.02 517975
# 2019-12-27 68.03 68.100 67.73 67.78 351118
# 2019-12-30 67.78 67.790 67.25 67.72 993865
# 2019-12-31 67.72 68.025 67.51 68.00 549672
#
# [1258 rows x 5 columns]
DataReader()の引数は以下のとおり。
name: ティッカーシンボル -str'GOOG','AAPL','MSFT'など
data_source: データソースの名前 -str'av-daily','av-daily-adjusted'(調整後終値)など
start: 取得したい期間の開始日時 -datetime.datetimeend: 取得したい期間の終了日時 -datetime.datetimeapi_key: APIキー -str
DataReader()は以下のファイルで定義されている。data_sourceに指定できるデータソース名などはコードを見るのが確実。特定のバージョンを確認したい場合はタグ(Tags)から選択すればよい。
ここではテキストファイルに記述したAPIキーを読み込んでいるが、もちろん他の手段を使ってもよい。公開しないのであればコード中にベタ書きしても構わない。
'av-daily'で指定した場合、取得できるデータ列は5項目(OHLCV)。
- open : 始値
- high : 高値
- low : 安値
- close : 終値
- volume: 出来高
data_sourceを'av-daily-adjusted'とするとadjusted close(調整後終値)などの列が追加される。期間中に株式分割が行われた場合などはこちらを使う。
以前はnameにティッカーシンボルのリストを指定して複数の銘柄を同時に取得できたが、Alpha Vantageでは対応していない模様。
複数の銘柄を比較したい場合は別途データを取得してから組み合わせればよい。
df_aapl = web.DataReader('AAPL', 'av-daily', start, end, api_key=api_key)
print(df_aapl)
# open high low close volume
# 2015-01-02 111.39 111.44 107.3500 109.33 53204626
# 2015-01-05 108.29 108.65 105.4100 106.25 64285491
# 2015-01-06 106.54 107.43 104.6300 106.26 65797116
# 2015-01-07 107.20 108.20 106.6950 107.75 40105934
# 2015-01-08 109.23 112.15 108.7000 111.89 59364547
# ... ... ... ... ... ...
# 2019-12-24 284.69 284.89 282.9197 284.27 12119714
# 2019-12-26 284.82 289.98 284.7000 289.91 23334004
# 2019-12-27 291.12 293.97 288.1200 289.80 36592936
# 2019-12-30 289.46 292.69 285.2200 291.52 36059614
# 2019-12-31 289.93 293.68 289.5200 293.65 25247625
#
# [1258 rows x 5 columns]
df_sne_aapl = pd.DataFrame({'SNE': df_sne['close'], 'AAPL': df_aapl['close']})
print(df_sne_aapl)
# SNE AAPL
# 2015-01-02 20.56 109.33
# 2015-01-05 20.26 106.25
# 2015-01-06 20.25 106.26
# 2015-01-07 21.53 107.75
# 2015-01-08 21.56 111.89
# ... ... ...
# 2019-12-24 67.76 284.27
# 2019-12-26 68.02 289.91
# 2019-12-27 67.78 289.80
# 2019-12-30 67.72 291.52
# 2019-12-31 68.00 293.65
#
# [1258 rows x 2 columns]
CSVで保存
pandas.DataFrameのto_csv()メソッドでCSVファイルとして保存できる。
df_sne.to_csv('data/src/sne_2015_2019.csv')
df_aapl.to_csv('data/src/aapl_2015_2019.csv')
df_sne_aapl.to_csv('data/src/sne_aapl_2015_2019.csv')
グラフをプロット
プロットするのも簡単。pandas.DataFrameのplot()メソッドを使う。
Alpha Vantageで取得できるpandas.DataFrameのindexは文字列だが、これをpd.to_datetime()でDatetimeIndexに変換して時系列データとしておくとプロット時のX軸を適切に調整してくれる。
If the index consists of dates, it calls gcf().autofmt_xdate() to try to format the x-axis nicely as per above. Visualization — pandas 1.0.3 documentation
時系列データにしておくと年や月で行を指定したりスライスで期間を抽出したりできるというメリットもある。
print(type(df_sne_aapl.index))
# <class 'pandas.core.indexes.base.Index'>
df_sne_aapl.index = pd.to_datetime(df_sne_aapl.index)
print(type(df_sne_aapl.index))
# <class 'pandas.core.indexes.datetimes.DatetimeIndex'>
df_sne_aapl.plot(title='SNE vs. AAPL', grid=True)
# plt.show()
plt.savefig('data/dst/pandas_datareader_stock.png')
plt.close()
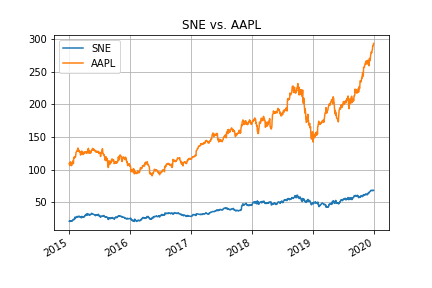
plt.savefig()は結果を画像ファイルとして保存する。表示させたい場合はplt.show()を使う。
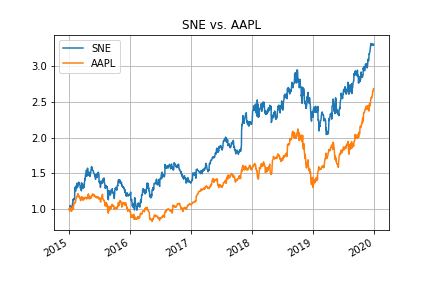
期間の初日で規格化する例は以下の通り。
df_sne_aapl['SNE'] /= df_sne_aapl['SNE'][0]
df_sne_aapl['AAPL'] /= df_sne_aapl['AAPL'][0]
df_sne_aapl.plot(title='SNE vs. AAPL', grid=True)
plt.savefig('data/dst/pandas_datareader_stock_normalize.png')
plt.close()
人口、GDPなど(World Bank)
データ取得
世界銀行(World Bank)が公開している人口、GDP、出生率などのマクロデータにアクセスできる。
例として日本とアメリカの人口を取得する。
from pandas_datareader import wb
import matplotlib.pyplot as plt
df = wb.download(indicator='SP.POP.TOTL', country=['JP', 'US'],
start=1960, end=2014)
print(df)
# SP.POP.TOTL
# country year
# Japan 2014 127276000
# 2013 127445000
# 2012 127629000
# 2011 127833000
# 2010 128070000
# ... ...
# United States 1964 191889000
# 1963 189242000
# 1962 186538000
# 1961 183691000
# 1960 180671000
#
# [110 rows x 1 columns]
wb.download()の引数は以下のとおり。
indicator: データのID(後述) -strcountry: 国名コード -strまたはstrのlist- 国名コードはISO 3166-1で定められている
start: 取得したい期間の開始年 -intend: 取得したい期間の終了年 -int
indicator
indicatorに指定するIDは世界銀行のサイトで検索できる。
検索窓から飛んだ先の個別ページURLの末尾がIDとなる。
例えば、CO2排出量の場合、検索窓に「CO2」と入力するといくつか候補が挙げられるので、「CO2 emissions (kt)」を選んで「Go」をクリックすると、個別ページが表示される。
indicatorに指定するIDは個別ページのURL(https://data.worldbank.org/indicator/EN.ATM.CO2E.KT)の末尾。この例の場合は'EN.ATM.CO2E.KT'となる。
主要な指標は「Indicators | Data」に列挙されているので、そこから選んでもよい。
階層データの整形
wb.download()で取得できるデータは階層型のマルチインデックスとなっている。グラフにプロットする場合などはこのままだと使いにくいので、unstack()で行から列へピボットする。
df2 = df.unstack(level=0)
print(df2.head())
# SP.POP.TOTL
# country Japan United States
# year
# 1960 92500572 180671000
# 1961 94943000 183691000
# 1962 95832000 186538000
# 1963 96812000 189242000
# 1964 97826000 191889000
print(df2.tail())
# SP.POP.TOTL
# country Japan United States
# year
# 2010 128070000 309321666
# 2011 127833000 311556874
# 2012 127629000 313830990
# 2013 127445000 315993715
# 2014 127276000 318301008
columnsはマルチインデックスのままなのでシンプルな形に変更する。
print(df2.columns)
# MultiIndex([('SP.POP.TOTL', 'Japan'),
# ('SP.POP.TOTL', 'United States')],
# names=[None, 'country'])
df2.columns = ['Japan', 'United States']
print(df2.head())
# Japan United States
# year
# 1960 92500572 180671000
# 1961 94943000 183691000
# 1962 95832000 186538000
# 1963 96812000 189242000
# 1964 97826000 191889000
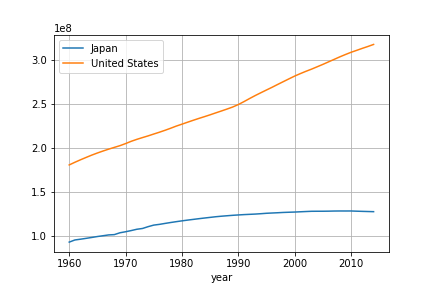
プロットすると以下のようになる。
df2.plot(grid=True)
plt.savefig('data/dst/pandas_datareader_wb.png')
plt.close()